LLM Tool Loops with OpenAI and Anthropic
Intro
In this post I will be using OpenAI and Anthropic APIs fpr LLM inference and function calling. First I will go into some differences between the OpenAI and Anthropic APIs. I will be using a wrapper I wrote for implementing tool calling loops.
Then I will apply function calling to a problem and run some evaluation. I'm going to do this in the context of working on a "synthetic" problem with synthetic data. This "fake" problem has some similarities related to some other projects I've been working on recently.
OpenAI and Anthropic APIs
Let's spend a bit of time going through some similarities and differences between the OpenAI and Anthropic APIs when using their LLMs for inference and function calling. I am quite familiar with the OpenAI API because I have been using it for more than a year. However, Anthropic's API is quite new to me. I think this is likely true for many people building with LLMs, simply because OpenAI was there to build upon first.
Recently I have started using Anthropic's latest model, claude-3-5-sonnet, through the browser interface. I really like it so I wanted to also learn to use it through the Python SDK. Anthropic's API documentation is great. Another great way to learn about the Anthropic python API is to read the source code for answer.ai's wrapper Claudette. Usually I would not point people to a wrapper to learn the underlying API but in this case the source code for Claudette is a readable notebook that walks you through all the code. I found this to be an amazing resource for learning the Anthropic python SDK.
My Own Wrapper with an Emphasis on the "Tool Calling Loop"
I have written my own wrapper classes around some functionality of OpenAI and Anthropic. Here are some reasons why I did this.
- The best way to learn is to write it yourself. The best wrapper is the one you write and test yourself, and fully understand.
- I wanted to write a wrapper that was focused on tool/function calling and provide a similar interface between OpenAI and Anthropic.
- I wanted to add in some features specific to tool calling such as parallel execution, and followup calls (tool calling loop).
You don't need to understand my OpenAI and Anthropic wrapper code to understand this blog post. I'm not going to show any of that code directly here, but I am going to use it. At the end of the day it's just using OpenAI and Anthropic python libraries for interacting with their models. The wrapper is not really what's important here. The focus will be on the tool calling loop. All of the code can be found here if you are intersted.
The Tool Calling Loop
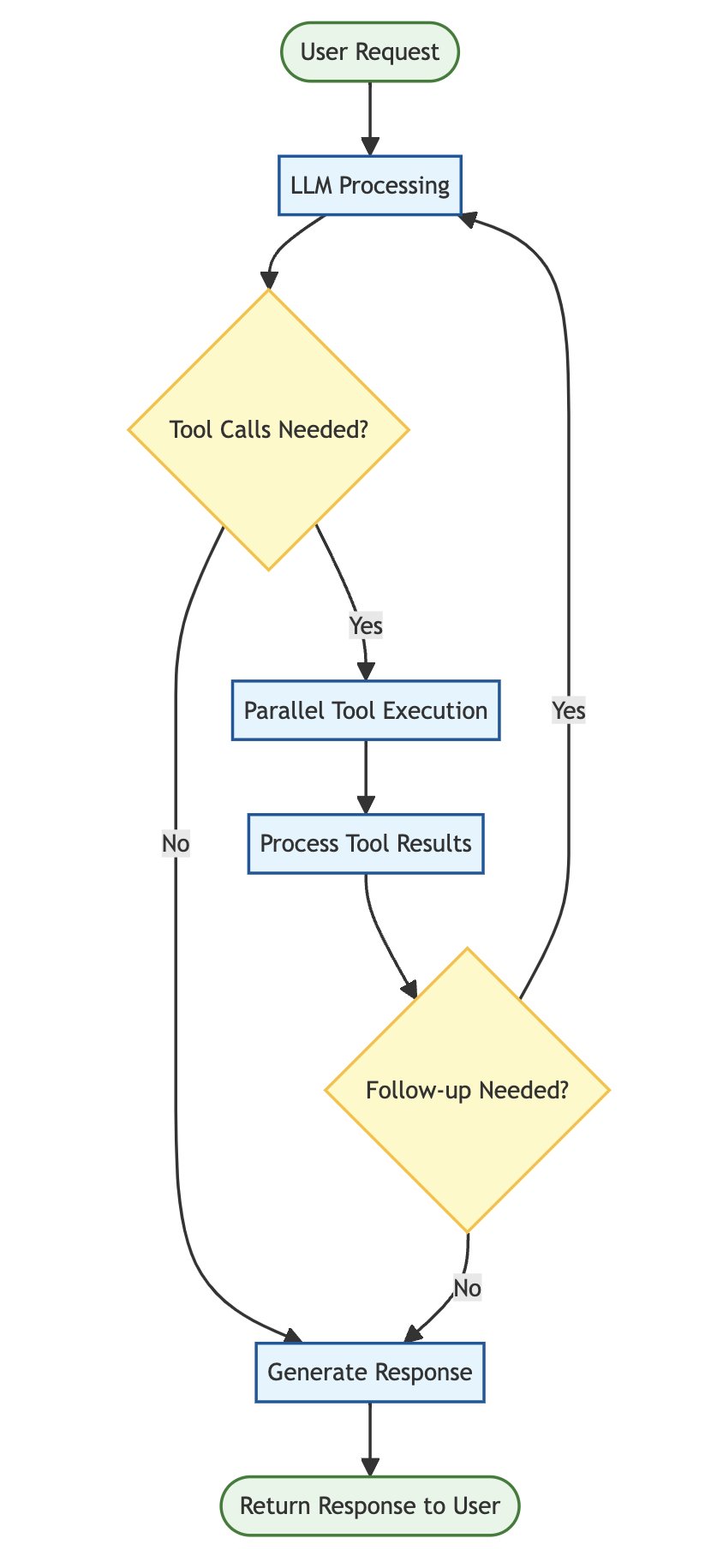 {width="45%" fig-align="center"}
{width="45%" fig-align="center"}
I want the tool calling loop in my wrapper to be able to do the following:
- Call functions in parallel when possible. For example, if the LLM says to call several tools which are independent of each other, then these functions should be executed in parallel (not sequentially).
- Handle followup tool calls if necessary. For example, if the output of one tool is required as the input to another tool, allow the LLM to decide if more followup tool calls are required.
- Work with both Anthropic and OpenAI tool calling, using a similar interface.
- Keep record of all the tool calls, the inputs, the outputs, etc. This is useful for debugging and for the evaluation.
That is essentially the "tool calling loop" with some custom logic for my own use case.
A simple example would be:
USER: I want to book a flight for Boston or New York. Pick the location that has the better weather. Thanks!
ASSISTANT:
- calls
get_weather(Boston)andget_weather(New York)independently and in parallel. - Picks the location with the best weather (Boston).
- calls
book_flight(Boston) - Provides final assistant message to user.
The tool calling loop bundles up this logic into a single python function.
API Differences
Let's start with comparing OpenAI chat completions and Anthropic message creations. I'm using my wrapper class here but all the basics/foundations are the same. The returned objects are just dictionaries and not the usual Pydantic objects. But it does not matter. If you have used either API before then all this will be pretty familiar.
The first major difference is that the system prompt has its own field argument for Anthropic. Whereas with the OpenAI messages format
you provide the system role as the first message. It's just personal preference but since I started with OpenAI, I like that way
of working with the system prompt. So the first thing I did with my Anthropic wrapper is implement the system prompt similar to how OpenAI does it.
This way I can pass similar messages objects to either wrapper as input. Let's make this clear through a demonstration.
from llm import AnthropicLLM, OpenAiLMM
llm_openai = OpenAiLMM()
llm_anthropic = AnthropicLLM()
resp = llm_openai.call(
messages=[{"role": "system", "content": "Talk like a pirate."}, {"role": "user", "content": "hey"}],
model="gpt-3.5-turbo-0125",
temperature=0.6,
max_tokens=150,
)
resp
resp = llm_anthropic.call(
messages=[{"role": "system", "content": "Talk like a pirate."}, {"role": "user", "content": "hey"}],
model="claude-3-5-sonnet-20240620",
temperature=0.6,
max_tokens=150,
)
resp
Also note that even things like temperature are different. For OpenAI its range is [0,2] whereas Anthropic it's [0,1]. The output token usages are different formats as well. Here I have made them the same, similar to OpenAI token usage format. I don't plan to go through all these differences in this post. Just some of the "big" ones.
The next big difference is how the message responses/outputs are returned. By default, OpenAI returns n=1 responses/choices for normal text generation. It returns the {'content': "...", 'role': 'assistant'} format. If there are tool calls then it returns those as a separate field tool_calls. But Anthropic returns all its content as a list of messages. Those message objects can have different types such as text, tool_use, tool_result, etc.
Let's go through the all too familiar weather example. It's like the "hello world" of function calling. Starting with OpenAI API tool format:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The location city",
},
},
"required": ["location"],
},
},
}
]
llm_openai.call(messages=[{"role": "user", "content": "What is the weather in Boston?"}], model="gpt-3.5-turbo-0125", tools=tools)
This is just the first step. The LLM says we need to call a tool and OpenAI uses this 'tool_calls' field.
Also note that OpenAI often leaves content as None when returning tools to be called. This is not always the case though!
When we make this same request with Anthropic we need to define the tools slightly different. It does not accept the same format. If we try and use the same format we get an error.
llm_anthropic.call(messages=[{"role": "user", "content": "What is the weather in Boston?"}], model="claude-3-5-sonnet-20240620", tools=tools)
I have a simple function to convert from OpenAI tool format to Anthropic tool format.
from copy import deepcopy
def convert_openai_tool_to_anthropic(open_ai_tool: dict):
t = deepcopy(open_ai_tool)
t = t["function"]
t["input_schema"] = t["parameters"]
t.pop("parameters")
return t
When using Anthropic we need to define the tools like this.
convert_openai_tool_to_anthropic(tools[0])
llm_anthropic.call(
messages=[{"role": "user", "content": "What is the weather in Boston?"}],
model="claude-3-5-sonnet-20240620",
tools=[convert_openai_tool_to_anthropic(tools[0])],
)
With the Anthropic output, the content field contains the tool calls and assistant messages together in the same list. There are different types on each object to tell them apart. I think sonnet is being prompted to use chain of thought prompting. That's why it explains itself and provides the content message of type text. You can try and change this by adding a system prompt.
llm_anthropic.call(
messages=[
{
"role": "system",
"content": "When calling tools/functions, do not talk about which ones you use or mention them.",
},
{"role": "user", "content": "What is the weather in Boston?"},
],
model="claude-3-5-sonnet-20240620",
tools=[convert_openai_tool_to_anthropic(tools[0])],
temperature=0,
)
Simple Tool Calling Loop Example
Let's now go through a tool calling loop example.
This tool calling loop in my wrapper is implemented in a function tool_loop. Let's consider the simple example
of using weather and flight booking tools together.
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The location city",
},
},
"required": ["location"],
},
},
},
{
"type": "function",
"function": {
"name": "book_flight",
"description": "Book a flight from one location to another.",
"parameters": {
"type": "object",
"properties": {
"departure_city": {
"type": "string",
"description": "The departure city.",
},
"arrival_city": {
"type": "string",
"description": "The arrival city.",
},
},
"required": ["departure_city", "arrival_city"],
},
},
},
]
def get_current_weather(location):
if "boston" in location.lower():
return {"data": "Sunny!"}
else:
return {"data": "Rainy!"}
def book_flight(departure_city, arrival_city):
return {"data": f"I have booked your flight from {departure_city} to {arrival_city}."}
functions_look_up = {"get_current_weather": get_current_weather, "book_flight": book_flight}
Above is what is needed for the tool calling loop defined in tool_loop.
The LLM will decide which tools to call, the arguments to use and so on.
The functions will be executed and the results will be passed back to the LLM.
Then the LLM will write the final assistant message. The tools/functions must return a dict with the key 'data',
which is the tool result content passed to the LLM.
First we will use OpenAI.
resp = llm_openai.tool_loop(
messages=[
{
"role": "user",
"content": """I need to book a flight from Halifax to either Boston or New York.
I want to fly to the city with the nicer weather. Please book my flight according to these requirements.
""",
}
],
tools=tools,
functions_look_up=functions_look_up,
model="gpt-3.5-turbo-0125",
temperature=0,
)
resp.keys()
resp['message']is the final assistant message after all the internal looping logic.
resp["message"]
resp['new_messages']is the record of all new messages created after the user message and up to and including the final assistant message. It is useful for keeping track of the conversation history in the format the API expects. It includes all the tool calls and interactions. It will be in the format expected by either OpenAI or Anthropic, depending on which API is being used. Note that this example is the OpenAI API format.
resp["new_messages"]
resp['tool_calls_details']is a dictionary with all the tool calls made, the results, the function names, and the input arguments. This is not used for passing to the LLM. Rather it's just my way of keeping track of all the tool calls. It's useful for debugging and future evaluation. I use this same format for OpenAI and Anthropic.
resp["tool_calls_details"]
- The other fields are
resp['token_usage'],resp['model'], andresp['execution_time']. They contain the token usage for the entirety of the interactions, the model used, and how long it took to execute the entire processtool_loop.
{k: v for k, v in resp.items() if k in ["token_usage", "model", "execution_time"]}
Now we can use the Anthropic wrapper I wrote to do the same tool call loop with Anthropic's claude sonnet 3.5. We just need to convert the tool format. Since I already explained all the fields returned, we will display the final result.
resp = llm_anthropic.tool_loop(
messages=[
{
"role": "user",
"content": """I need to book a flight from Halifax to either Boston or New York.
I want to fly to the city with the nicer weather. Please book my flight according to these requirements.
""",
}
],
tools=[convert_openai_tool_to_anthropic(t) for t in tools],
functions_look_up=functions_look_up,
model="claude-3-5-sonnet-20240620",
temperature=0,
)
resp
It's kind of neat to see the chain of thought and reasoning. But it depends on the application whether you want all that extra token usage. I hope this helps you understand some differences between Anthropic's and OpenAI APIs when it comes to tool calling. Next we will continue looking at a different and more difficult problem with tool calling.
Problem Description
All of this data for this next problem has been synthetically created. I was using Anthropic's claude-3-5-sonnet in the browser and just hacking together some prompts and copying/pasting data. It could have been streamlined, but unfortunately I didn't really document this part. Now let's get on with the problem description.
Suppose there is an ecommerce platform connected to backend APIs, databases, etc. The backend data contains various metrics, brands, and sales channels. Also assume that the platform has a front end, allowing users to create dashboards and reports with the data.
Then one day, the platform developers jump on the generative AI hype train, and decide they want to add a natural language interface to the platform. The goal is so that users can ask questions and get answers using the same ecommerce data.
Now let's go through some of the data and explain it.
import pandas as pd
from ecommerce import brands, ecommerce_metrics, questions, sales_channels
from itables import show
Metrics
When a user asks a question it will be about at least one of these metrics.
The user will use some natural description to reference these metrics. Possibly using similar wording to the name or description columns below.
Then there is an associated enum value for each metric which is used in the backend when calling the backend APIs. There are about 150 metrics.
ecommerce_metrics_df = pd.DataFrame(ecommerce_metrics)
show(ecommerce_metrics_df)
Brands
Then there is the concept of brands, of which I have generated around 130 or so.
brands_df = pd.DataFrame(brands)
show(brands_df)
Sales Channels
Finally, we have some various sales channels. These are different channels which sales are made through. Each sale channel has the same associated fields. The number of sales channels is designed to be much less than the number of metrics and brands.
sales_channels_df = pd.DataFrame(sales_channels)
show(sales_channels_df)
Example User Questions
Given this data, I used Anthropic's claude-3-5-sonnet to generate some questions users could ask. The questions can mention the metrics, brands, sales channels, as well as a time dimension. For each question there is the "ground truth" expected metrics, brands, sales channels, and time range. This ground truth will be used later on when we do evaluation. Just scroll to the right in the table below to see the other fields/columns.
questions_df = pd.DataFrame(questions)
show(questions_df)
Solution Approach #1
Let's first try and solve this problem by shoving most of the information into a system prompt.
import random
from concurrent.futures import ThreadPoolExecutor, as_completed
import numpy as np
from tqdm import tqdm
metrics_str = "\n".join([f"{m['enum']}: {m['description']}" for m in ecommerce_metrics])
brands_str = "\n".join([f"{b['enum']}: {b['description']}" for b in brands])
channels_str = "\n".join([f"{c['enum']}: {c['description']}" for c in sales_channels])
system_prompt = f"""
You will be asked a question by the user about retrieving ecommerce data.
Use the available tools but only call the tools when needed.
If you need further clarification then ask.
There are hundreds of metrics and hundreds of brands in the backend system.
The user will not know all these metrics and brands, or how to refer to them exactly.
I will list them out here for you and you can pick the most appropriate ones
based on the users request.
ECOMMERCE METRICS:
{metrics_str}
BRANDS:
{brands_str}
SALES CHANNELS:
{channels_str}
In general you will follow the typical flow when answering questions:
Extract the user requested metric, brand(s), and sales channels.
Pass the relevant arguments into the get_ecommerce_data tool.
Today's date is Monday, June 10, 2024
"""
This makes the system prompt quite long. We can print part of it.
print(system_prompt[:1000])
print("\n\n......\n\n")
print(system_prompt[-1000:])
Next we define the tool using the OpenAI format.
get_ecommerce_data_tool = {
"type": "function",
"function": {
"name": "get_ecommerce_data",
"description": """Get the sales data from the backend system.""",
"parameters": {
"type": "object",
"properties": {
"backend_metric": {
"type": "string",
"description": "This is the backend metric ENUM.",
},
"backend_brands": {
"type": "array",
"items": {
"type": "string",
},
"default": [],
"description": "The list of backend ENUM brands.",
},
"sales_channels": {
"type": "array",
"items": {
"type": "string",
"enum": [x["enum"] for x in sales_channels],
},
"default": [],
"description": "The list of sales channels.",
},
"current_period_start_date": {
"type": "string",
"description": "The start of the current reporting period.",
},
"current_period_end_date": {
"type": "string",
"description": "The end of the current reporting period.",
},
},
"required": [
"backend_metric",
],
},
},
}
tools_openai = [get_ecommerce_data_tool]
tools_anthropic = [convert_openai_tool_to_anthropic(t) for t in tools_openai]
def get_ecommerce_data(*args, **kwargs):
# some dummy data
return {"data": random.randint(0, 10)}
functions_look_up = {"get_ecommerce_data": get_ecommerce_data}
We can pass one question through both OpenAI and Anthropic and see how the tool loop does:
questions[0]
llm_resp = llm_openai.tool_loop(
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": questions[0]["question"],
},
],
tools=tools_openai,
functions_look_up=functions_look_up,
model="gpt-3.5-turbo-0125",
)
llm_resp
llm_resp = llm_anthropic.tool_loop(
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": questions[0]["question"],
},
],
tools=tools_anthropic,
functions_look_up=functions_look_up,
model="claude-3-5-sonnet-20240620",
)
llm_resp
Here is an evaluation we can use to see if the LLM is extracting the correct arguments. It does not eval
the final assistant message. It's just straight up classification accuracy on whether the
arguments for the tool get_ecommerce_data were correctly extracted. It's also assuming a simpler scenario
and only considering one call of get_ecommerce_data.
def eval_llm_resp(question: dict, llm_resp: dict):
if not llm_resp.get("tool_calls_details"):
args_predicted = dict()
else:
args_predicted = [x["input"] for x in llm_resp["tool_calls_details"].values() if x["name"] == "get_ecommerce_data"]
args_predicted = args_predicted[0] if args_predicted else {}
return {
"question": question["question"],
"expected_metric": question["expected_metric"],
"predicted_metric": args_predicted.get("backend_metric", ""),
"metric_correct": question["expected_metric"] == args_predicted.get("backend_metric", ""),
"expected_brands": sorted(question["expected_brands"]),
"predicted_brands": sorted(args_predicted.get("backend_brands", [])),
"brands_correct": sorted(question["expected_brands"]) == sorted(args_predicted.get("backend_brands", [])),
"expected_sales_channels": sorted(question["expected_sales_channels"]),
"predicted_sales_channels": sorted(args_predicted.get("sales_channels", [])),
"sales_channels_correct": sorted(question["expected_sales_channels"]) == sorted(args_predicted.get("sales_channels", [])),
"expected_current_period_start_date": question["current_period_start_date"],
"predicted_current_period_start_date": args_predicted.get("current_period_start_date", ""),
"current_period_start_date_correct": question["current_period_start_date"] == args_predicted.get("current_period_start_date", ""),
"expected_current_period_end_date": question["current_period_end_date"],
"predicted_current_period_end_date": args_predicted.get("current_period_end_date", ""),
"current_period_end_date_correct": question["current_period_end_date"] == args_predicted.get("current_period_end_date", ""),
}
def eval_questions(llm, model, tools, questions: list[dict], max_workers=10):
def task(question: dict):
llm_resp = llm.tool_loop(
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": question["question"],
},
],
tools=tools,
functions_look_up=functions_look_up,
model=model,
)
llm_resp.update(eval_llm_resp(question, llm_resp))
return llm_resp
eval_res = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(task, question) for question in questions]
for future in tqdm(as_completed(futures), total=len(questions), desc="Evaluating questions"):
eval_res.append(future.result())
return eval_res
def calculate_accuracies(df):
accuracies = {}
for col in df.columns:
if col.endswith("_correct"):
accuracy = df[col].sum() / df.shape[0]
accuracies[col.replace("correct", "accuracy")] = f"{accuracy:.2%}"
return accuracies
Evaluating gpt-3.5-turbo-0125
df_openai = pd.DataFrame(eval_questions(llm_openai, "gpt-3.5-turbo-0125", tools_openai, questions, max_workers=10))
You have to scroll far to the right here because there are many columns. But take a look at the expected_ and predicted_ columns in particular. It's very useful for looking at the data and debugging any issues.
show(df_openai)
calculate_accuracies(df_openai)
Let's see where it's making some mistakes on the sales channels.
mistakes = df_openai[~df_openai["sales_channels_correct"]]
show(mistakes[["question", "expected_sales_channels", "predicted_sales_channels", "token_usage", "execution_time"]])
We can take a look at some of these tool calls in detail:
df_openai.loc[mistakes.index, ["expected_sales_channels", "new_messages"]][:3].to_dict(orient="records")
It looks like these are examples where the LLM made multiple separate tool calls, one for each sales channel. Our evaluation is a little too simplistic since it only grabs one tool call to extract the arguments. We are marking some of these as incorrect, but they could actually be correct if they are applying the correct sales channels over multiple calls.
Evaluating gpt-4o-mini
UPDATE 2024-07-19: This model came out recently, so I went back and updated this post to evaluate it.
df_openai = pd.DataFrame(eval_questions(llm_openai, "gpt-4o-mini", tools_openai, questions, max_workers=10))
show(df_openai)
calculate_accuracies(df_openai)
mistakes = df_openai[~df_openai["sales_channels_correct"]]
show(mistakes[["question", "expected_sales_channels", "predicted_sales_channels", "token_usage", "execution_time"]])
NOTE: The lower accuracy is because my evaluation is a little too simplistic since it only grabs one tool call to extract the arguments.
Evaluting claude-3-5-sonnet-20240620
Let's run the eval with Anthropic now. At the moment I keep getting rate limiting errors because I am on a lower tier with Anthropic. So it takes longer because I have to do one request at a time.
df_anthropic = pd.DataFrame(eval_questions(llm_anthropic, "claude-3-5-sonnet-20240620", tools_anthropic, questions, max_workers=1))
calculate_accuracies(df_anthropic)
show(df_anthropic)
Solution Approach #2
In the last approach I copy and pasted all the metrics, brands, and their descriptions into the system prompt. This was using a lot of tokens. And what if there were thousands of metrics and brands? Then it may not be reasonable to put them all in the system prompt. Checkout the token usage for OpenAI for example in the last approach:
show(df_openai[["execution_time", "token_usage"]])
Here is the token usage for Anthropic.
show(df_anthropic[["execution_time", "token_usage"]])
We can see that the requests used quite a fair bit of tokens in those tool loops. Another approach which I will look at here is the following:
- Do not list metrics and brands in the system prompt.
- Let the LLM extract what it assumes are metrics and brands.
- Define other tools/logic which will take the proposed metrics/brands and then return the most likely ones (enum values).
- The LLM can then choose the most appropriate from a handful of enum versioned metrics and brands.
We will use text embeddings to do this. We will compute text embeddings for the metrics and brands
and store them in numpy arrays. Then the LLM will extract metric: revenue, for example. We compute the embedding
for revenue and then return the k nearest metrics based on embedding distance. Then the LLM can pick the metric which is most appropriate.
We will define a new system prompt and some new tools to begin this approach.
system_prompt = """
You will be asked a question by the user about retrieving ecommerce data.
Use the available tools but only call the tools when needed.
If you need further clarification then ask.
There are hundreds of metrics and hundreds of brands in the backend system.
The user will not know all these metrics and brands or how to refer to them exactly.
You do not know all of them either, so I have provided some helper tools for you.
In general you will follow the typical flow when answering questions:
1. Extract the user requested metric, user requested brand(s), and the user requested sales channels.
2.
a) Pass the user requested metric to the the tool get_backend_metric to
get the list of most likely corresponding backend metric ENUMs.
Then choose the most appropriate from this list.
b) Pass the user requested brand(s) to the the tool get_backend_brands to
get the list of most likely corresponding backend brand ENUMs.
Then choose the most appropriate from this list.
3. Pass all the relevant arguments into the get_ecommerce_data tool.
Today's date is Monday, June 10, 2024
"""
We will compute the text embeddings for each brand and metric using the name and enum fields concatenated together.
def prepare_embedding_input(rec):
return f'{rec["name"]} {rec["enum"]}'
ecommerce_metrics[0]
input_text = prepare_embedding_input(ecommerce_metrics[0])
input_text
We will use text embeddings offered through OpenAI because it's quick and easy, and we are only creating hundreds of embeddings.
vec = llm_openai.get_embeddings([input_text])
print(vec)
print(vec.shape)
ecommerce_metrics_embeddings = llm_openai.get_embeddings([prepare_embedding_input(rec) for rec in ecommerce_metrics])
brands_embeddings = llm_openai.get_embeddings([prepare_embedding_input(rec) for rec in brands])
print(ecommerce_metrics_embeddings.shape)
print(brands_embeddings.shape)
get_backend_metric_tool = {
"type": "function",
"function": {
"name": "get_backend_metric",
"description": """Takes in the user requested metric and
uses ML/AI to return the k nearest neighbors for the most likely related backend ENUM metrics.""",
"parameters": {
"type": "object",
"properties": {
"user_requested_metric": {
"type": "string",
"description": "The metric requested by the user.",
},
},
"required": ["user_requested_metric"],
},
},
}
get_backend_brands_tool = {
"type": "function",
"function": {
"name": "get_backend_brands",
"description": """Takes in the user requested brand(s) and
uses ML/AI to return the k nearest neighbors for the most likely related backend ENUM brands per requested brands.""",
"parameters": {
"type": "object",
"properties": {
"user_requested_brands": {
"type": "array",
"items": {
"type": "string",
},
"default": [],
"description": "The list of brand(s) requested by the user.",
},
},
"required": ["user_requested_brands"],
},
},
}
def find_k_nearest_neighbors(embeddings, input_embedding, k):
# Calculate distances
distances = np.linalg.norm(embeddings - input_embedding, axis=1)
# Get indices of k smallest distances
nearest_indices = np.argpartition(distances, k)[:k]
# Sort the k nearest indices by distance
nearest_indices = nearest_indices[np.argsort(distances[nearest_indices])]
return nearest_indices
def get_backend_metric(user_requested_metric: str):
return {
"data": [
ecommerce_metrics[i]
for i in find_k_nearest_neighbors(llm_openai.get_embeddings([user_requested_metric]), ecommerce_metrics_embeddings, 3)
]
}
def get_backend_brands(user_requested_brands: list[str]):
data = dict()
for brand in user_requested_brands:
data[brand] = [brands[i] for i in find_k_nearest_neighbors(llm_openai.get_embeddings([brand]), brands_embeddings, 3)]
return {"data": data}
tools_openai = [get_backend_metric_tool, get_backend_brands_tool, get_ecommerce_data_tool]
tools_anthropic = [convert_openai_tool_to_anthropic(t) for t in tools_openai]
functions_look_up = {"get_backend_metric": get_backend_metric, "get_backend_brands": get_backend_brands, "get_ecommerce_data": get_ecommerce_data}
Let's quickly check that our tools for finding the metrics and brands are working properly.
We can pass in a list of brands and then get the most likely brands for each. Here we are returning
the k=3 nearest neighbors.
get_backend_brands(["shopify", "nike"])
We can also get the most likely enum metric objects:
get_backend_metric("revenue")
Looks like that's working. Before we run the entire evaluation on this second approach, let's pass one question through the tool loop as a manual test.
questions[0]
llm_resp = llm_openai.tool_loop(
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": questions[0]["question"],
},
],
tools=tools_openai,
functions_look_up=functions_look_up,
model="gpt-3.5-turbo-0125",
)
llm_resp
llm_resp = llm_anthropic.tool_loop(
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": questions[0]["question"],
},
],
tools=tools_anthropic,
functions_look_up=functions_look_up,
model="claude-3-5-sonnet-20240620",
)
llm_resp
Let's run the evaluation to see how this approach does in general.
Evaluating gpt-3.5-turbo-0125
df_openai = pd.DataFrame(eval_questions(llm_openai, "gpt-3.5-turbo-0125", tools_openai, questions, max_workers=10))
show(df_openai)
calculate_accuracies(df_openai)
Evaluating gpt-4o-mini
UPDATE 2024-07-19: This model came out recently, so I went back and updated this post to evaluate it.
df_openai = pd.DataFrame(eval_questions(llm_openai, "gpt-4o-mini", tools_openai, questions, max_workers=10))
show(df_openai)
calculate_accuracies(df_openai)
Evaluating claude-3-5-sonnet-20240620
And for Anthropic:
df_anthropic = pd.DataFrame(eval_questions(llm_anthropic, "claude-3-5-sonnet-20240620", tools_anthropic, questions, max_workers=1))
show(df_anthropic)
calculate_accuracies(df_anthropic)
Let's look at the token usage and execution time.
show(df_openai[["execution_time", "token_usage"]])
show(df_anthropic[["execution_time", "token_usage"]])
The execution time has gone up. We are using more tools and calling out to OpenAI for embeddings within those tools. But the results are still great, and now we are generating around 75% less tokens. Both approaches have pros and cons depending on the requirements and situation.
Chat Bot with Tool Loop
It's really easy to make a chatbot which uses this tool loop wrapper:
system_prompt = (
system_prompt
+ "\n\n Do not be wordy in your responses or discuss the tools. Do not offer suggestions or external analysis. Simply report on the data and be concise."
)
message_history = [{"role": "system", "content": system_prompt}]
while True:
user_message = input("USER: ")
message_history.append({"role": "user", "content": user_message})
print(f"USER: {user_message}\n\n")
llm_resp = llm_anthropic.tool_loop(
messages=message_history,
tools=tools_anthropic,
functions_look_up=functions_look_up,
model="claude-3-5-sonnet-20240620",
)
message_history.extend(llm_resp["new_messages"])
print(f"ASSISTANT: {llm_resp['message']['content']}\n\n")
if user_message.lower() == "stop":
break
message_history
Conclusion
I really enjoyed doing a deep dive into function calling and comparing the OpenAI and Anthropic APIs. It was fun to write a consistent wrapper to access both GPT and Claude Sonnet for tool calling inference. I also like this idea of using the KNN approach with text embeddings for working with data that may be too long to put into system prompts. I know that RAG is a common approach but here we were doing something slightly different within tool calls. I also showed how tool calling, which gives structured outputs, can be evaluated using simple metrics such as accuracy.