My Blog
Some Random Things I'm Interested In


Deploying a Remote MCP Server to Modal
Deploying a remote MCP server to Modal, and connecting it to hosts such as Claude Desktop and Cursor.


Subliminal Learning Paper - Reproducing a Simple Example
In this blog post I take a quick hack at reproducing a simple example from the Subliminal Learning paper.

Agents - Part 2 - OpenAI Responses API and Agent SDK
In this blog post I take a look into the new OpenAI responses API and the new OpenAI Agent SDK.
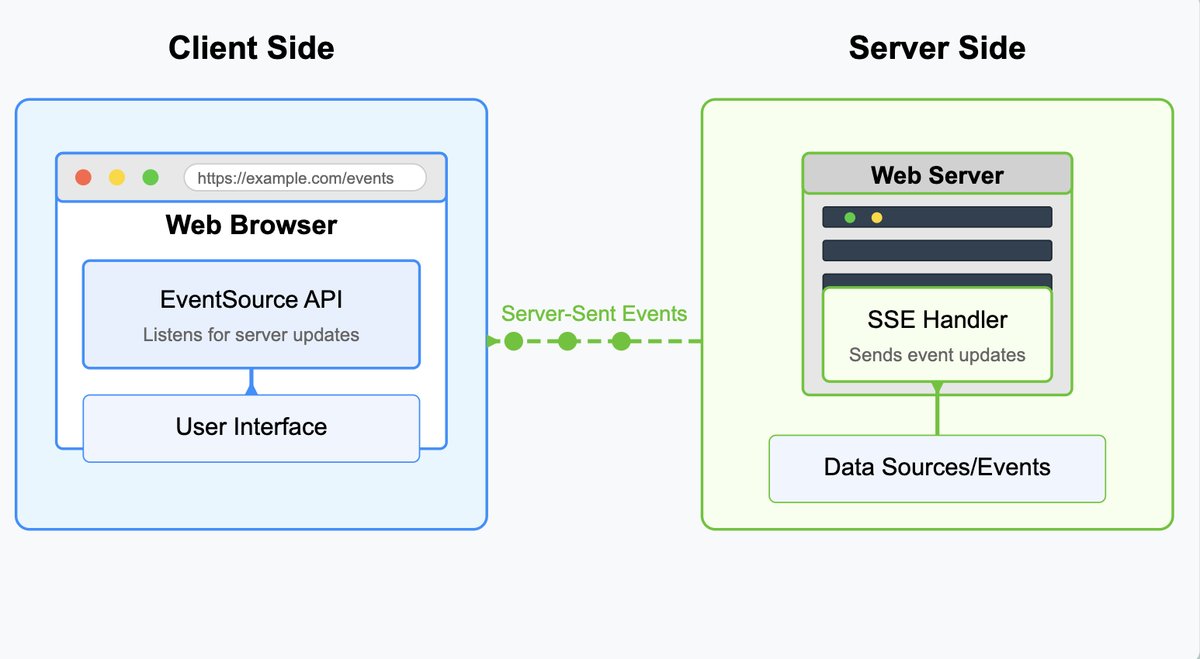
The Basics of Server-Sent Events (SSE) with FastHTML
In this blog post, I learn more about Server-Sent Events (SSE) in FastHTML and go through some examples.

Migrating My Blog from Quarto to fastHTML and MonsterUI
In this blog post, I walk through the process of migrating my blog from Quarto to fastHTML.

China AI Labs - Model Releases - 2025-01
In this blog post, I quickly jot down notes on the recent AI model releases from Chinese labs DeepSeek and Qwen, covering DeepSeek-R1 and Janus-Pro, but getting particularly excited about the feature-rich Qwen2.5 VL and my plans to deploy it on Modal.

Agents - Part 1
In this blog post, I explore the concept of AI agents, starting with various definitions and then diving into practical implementations like tool calling loops, ReAct prompting, and code agents, demonstrating these with models like gpt-4o-mini and Claude. I also touch upon the importance of secure sandbox environments for code execution in agentic workflows, providing a hands-on introduction to building simple agents without relying on complex frameworks.

Fine-Tuning ModernBERT For Classification Tasks on Modal
In this blog post, I walk through fine-tuning the ModernBERT model for classification tasks using Modal, detailing the setup process, providing code examples for data handling and model training, and aiming to be a practical guide for developers.

Gemini 2.0 Flash
In this blog post, I take a first look at Google's Gemini 2.0 Flash, noting its multimodal input and output capabilities, agentic features, and tool use, and I explore getting an API key, streaming content, multi-turn chats, function calling, and audio file uploads using the new Python SDK, highlighting my initial experiences and excitement for future exploration.

Passing Images into LLMs
In this blog post, I explore how images are processed in multimodal LLMs, starting with a recap of text processing in transformers, then delving into Vision Transformers (ViTs) and CLIP models to understand image encoding and cross-modal embeddings, and finally discussing how image patch embeddings are integrated into decoder LLMs for vision-language tasks.

PDF Q&A App using ColPali, Modal, and FastHTML
In this blog post, I detail building a PDF Q&A application using ColPali for vision-based document retrieval, Modal for scalable backend deployment, and FastHTML for a simple frontend, showcasing how these technologies combine to create an interactive tool for querying PDF documents.

🚀 Building with Modal 🚀
In this blog post, I share my excitement about Modal, a serverless platform, and demonstrate its capabilities by building a Flux image generation app and a multimodal RAG application for PDF Q&A using ColPali and Qwen2-VL, highlighting Modal's ease of use, scalability, and efficient GPU utilization.

LLM Tool Loops with OpenAI and Anthropic
In this blog post, I dig into the nuances of LLM tool loops using both OpenAI and Anthropic APIs, comparing their functionalities and showcasing a custom wrapper I built to streamline tool calling, including parallel execution and handling follow-up calls, all demonstrated with practical examples and a synthetic ecommerce problem.

Memory Usage for Quantized LLMS
In this blog post, I share my learnings about memory usage in quantized LLMs from a recent conference, covering bits and bytes, memory usage during inference and training, and exploring techniques like quantization and PEFT methods such as QLORA to reduce memory footprint while fine-tuning models like llama3-8B.

Fine-Tuning LLMs with Axolotl on JarvisLabs
In this blog post, I describe my experience fine-tuning an instruction-following LLM using Axolotl on JarvisLabs, detailing the setup process, dataset preparation, training, and inference, providing a hands-on guide to get started with LLM fine-tuning in the cloud.
Intro to LLMs
In this lunch and learn presentation I provide an introduction to LLMs for developers covering topics such as NLP history, word embeddings, transformer architecture, tokenization, base vs. instruction models, OpenAI-compatible inference, chat templates, structured output, function calling, RAG, multimodal capabilities, code interpreter, and fine-tuning.

Using Modal to Transcribe YouTube Videos with Whisper
In this blog post, I share my first experience using Modal to build a YouTube video transcription app with OpenAI Whisper, detailing the setup, code implementation for video download, transcription, and storage on S3, and highlighting Modal's seamless serverless execution and ease of use.

Getting Started with Axolotl for Fine-Tuning LLMs
In this blog post, I share my beginner's experience fine-tuning an LLM using the Axolotl library, detailing the setup on RunPod, configuration of the YAML file, dataset preprocessing, training, and inference, providing a starting point for others new to LLM fine-tuning.

Function Calling with Hermes-2-Pro-Mistral-7B
In this blog post, I explore function calling with the open-source LLM Hermes-2-Pro-Mistral-7B, detailing the setup, inference using an OpenAI-compatible class, defining tools/functions, and testing its function calling capabilities with various example questions.

OpenAI Compatible LLM Inference
In this blog post, I explore OpenAI-compatible LLM inference, demonstrating how to use the OpenAI Python client with various services like OpenAI, Together AI, Hugging Face Inference Endpoints, and Ollama, and I also introduce the instructor library for structured output, providing a unified approach to interact with different LLMs.

DSPy
In this blog post, I introduce DSPy, a library for prompt optimization, and walk through a practical example using the BIG-Bench Hard dataset and OpenAI's gpt-3.5-turbo-0125, demonstrating how to set up a basic QA module, evaluate its performance, and optimize it using DSPy's BootstrapFewShotWithRandomSearch teleprompter to improve accuracy.
Basic Transformer Architecture Notes
In this blog post, I provide notes on the basic transformer architecture, covering tokenization, input embeddings, self-attention, multi-head attention, feed-forward networks, and a simple implementation of a transformer-based language model trained for next token prediction using the TinyStories dataset.