Basic Transformer Architecture Notes
Intro
Here are some notes on the basic transformer architecture for my personal learning and understanding. Useful as a secondary resource, not the first stop. There are many resources out there, but here are several I enjoyed learning from:
- Chapter 3 of the book Natural Language Processing With Transformers [@tunstall2022natural]
- Andrej Karpathy's video Let's build GPT: from scratch, in code, spelled out [@karpathy_youtube_2023_gpt]
- Sebastian Raschka's Blog Post Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs [@SebastianRaschkaUnderstandingAttention]
- Omar Sanseviero's Blog Post The Random Transformer [@OmarSansevieroBlogRandomTransformer]
- The Illustrated Transformer [@TheIllustratedTransformerGlob]
- The original paper: Attention Is All You Need [@vaswani2017attention]
- Transformer Explainer Web UI and short paper [@cho2024transformerexplainerinteractivelearning]
Tokenization and Input Embeddings
In diagrams and code comments I will use the symbols:
Bfor batch size,batch_sizeTfor sequence length,seq_lengthi.e. "time dimension"Cfor embedding dimension,embed_dimi.e. "channel dimension"Vfor vocabulary size,vocab_sizeHfor head dimension,head_dimension
from math import sqrt
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoTokenizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
vocab_size = tokenizer.vocab_size # will also denote as V
seq_length = 16 # will also denote sequence length as T i.e. "time dimension"
embed_dim = 64 # will also denote as C i.e. "channel dimension"
num_heads = 8
head_dim = embed_dim // num_heads # will also denote as H
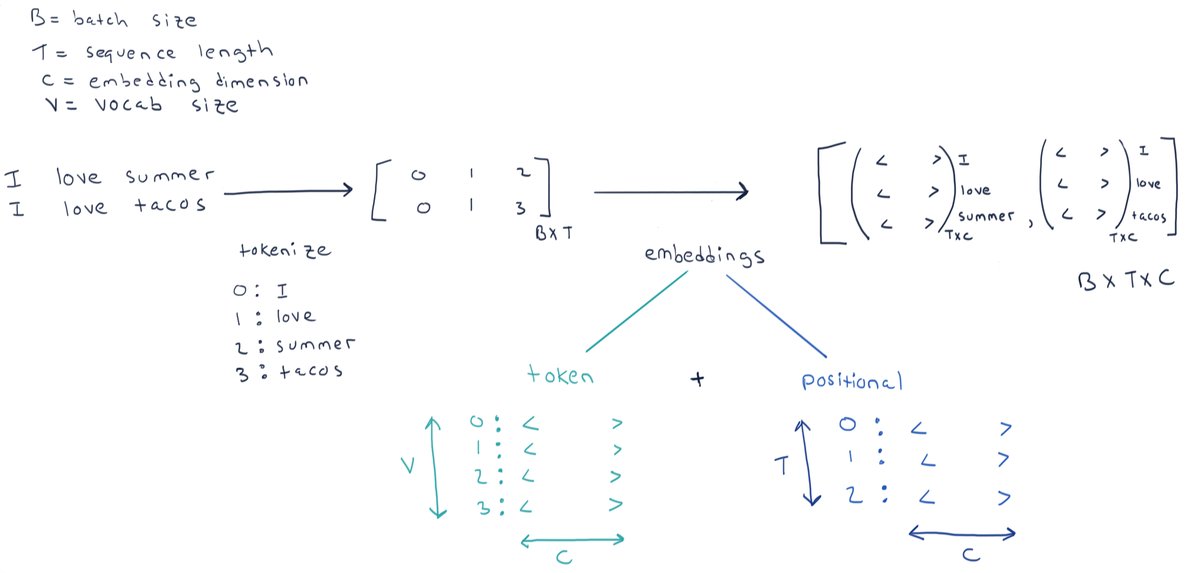
- Tokenize the input text to obtain tensor of token ids of shape
(B, T). - Convert each token to its corresponding token embedding.
- The look-up token embedding table has shape
(V, C).
- The look-up token embedding table has shape
- It's common to use a positional embedding along with the token embedding.
- Because the attention mechanism does not take position of the token into account.
- The look-up positional embedding table has shape
(T, C).
- The input embedding for a token is the token embedding plus the positional embedding.
- The embeddings are learned during training of the model.
texts = [
"I love summer",
"I love tacos",
]
inputs = tokenizer(
texts,
return_tensors="pt",
padding="max_length",
max_length=seq_length,
truncation=True,
).input_ids
inputs
- The above tokenizer settings will force each batch to have the same shape.
- Each row of
inputscorresponds to one of the elements in the input listtexts. - Each element of the tensor is a token id from the tokenizer vocabulary.
- The vocabulary size is typically in the range of 30,000 to 50,000 tokens.
- The number of columns is the sequence length for the batch.
print(inputs.shape) # (B, T)
print(vocab_size)
for row in inputs:
print(tokenizer.convert_ids_to_tokens(row))
Now that the text is tokenized we can look up the token embeddings. Here is the look-up token embedding table:
token_emb = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embed_dim)
token_emb # (V, C)
Get the token embeddings for the batch of inputs:
token_embeddings = token_emb(inputs)
token_embeddings.shape # (B, T, C)
There are various methods for positional embeddings, but here is a very simple approach.
positional_emb = nn.Embedding(num_embeddings=seq_length, embedding_dim=embed_dim) # (T, C)
positional_embeddings = positional_emb(torch.arange(start=0, end=seq_length, step=1))
positional_embeddings.shape # (T, C)
Using broadcasting, we can add the two embeddings (token and positional) to get the final input embeddings.
token_embeddings.shape # (B, T, C)
embeddings = token_embeddings + positional_embeddings
embeddings.shape
Self Attention
- Go watch Andrej Karpathy's explanation of Self Attention here [@karpathy_youtube_2023_gpt] in the context of a decoder only network.
- Self-attention in transformer models computes a weighted average of the words/tokens in the input sequence for each word. The weights are determined by the relevance or similarity of each word/token pair, allowing the model to focus more on certain words/tokens and less on others.
- Decoder only models are autoregressive. They generate outputs one step at a time and use current and previous outputs as additional input for the next step. We use the mask to mask out future tokens (tokens on the right). For encoder only networks, which are often used for classification tasks, all tokens in the sequence can be used in the calculation of attention.
- There is no notion of space/position in self attention calculation (that is why we use the positional embeddings).
- Each example across the batch dimension is processed independently (they do not "talk" to each other).
- This attention is self-attention because the queries, keys, and values all came from the same input source. It involves a single input sequence.
- Cross-attention involves two different input sequences (think encoder-decoder for translation for example). The keys and values can come from a different source.
- Dividing by the
sqrtof the head size, is to prevent the softmax from becoming. It controls the variance of the attention weights and improves stability of training.

We begin with our input embeddings:
# our embeddings input: (B, T, C)
embeddings.shape
query = nn.Linear(in_features=embed_dim, out_features=head_dim, bias=False)
key = nn.Linear(in_features=embed_dim, out_features=head_dim, bias=False)
value = nn.Linear(in_features=embed_dim, out_features=head_dim, bias=False)
# projections of the original embeddings
q = query(embeddings) # (B, T, head_dim)
k = key(embeddings) # (B, T, head_dim)
v = value(embeddings) # (B, T, head_dim)
q.shape, k.shape, v.shape
- Use the dot product to find the similarity between all the projected input embeddings for a given sequence.
- Each sequence in the batch is processed independently.
qandkboth have shape(B, T, H)so we take the transpose ofkwhen multiplying the matrices to get the dot products.
w = (q @ k.transpose(-2, -1)) / sqrt(head_dim) # (B, T, T) gives the scores between all the token embeddings within each batch
# optional mask
tril = torch.tril(torch.ones(seq_length, seq_length))
w = w.masked_fill(tril == 0, float("-inf"))
# normalize weights
w = F.softmax(w, dim=-1) # (B, T, T)
w.shape
- For each sequence in the batch, there is a corresponding
(T, T)tensor of attention scores. These are the weights to use in the weighted average (linear combination) of the projected input embeddings.
# weighted average (linear combination) of the projected input embeddings
out = w @ v
out.shape
- In summary, for a single attention head, an input embedding tensor of shape
(B, T, C)was transformed to an output tensor of shape(B, T, H).
Multi Head Attention
- There are multiple attention heads, each with their own independent queries, keys, values.
- Each attention head takes the input embeddings of shape
(B, T, C)and produces an output(B, T, H). - Concatenate the outputs from each head so that the concatenated tensor is back to the original input shape
(B, T, C). - Once we have the concatenated output tensor, we put it through a linear projection,
nn.Linear(embed_dim, embed_dim)to get the output from the multi head attention: a tensor of shape(B, T, C).
Feed forward layer (FFN)
- The output from the Multi-head attention is
(B, T, C). - This is then fed through a 2 layer feed forward network (FFN).
- Rule of thumb is for the first layer to have a hidden size of 4 times the embedding dimension
- often
nn.GELU()(smoother version of RELU) is used for the non-linearity. - Usually
nn.Linearis applied to a tensor of shape(batch_size, input_dim)and acts on each row/vector independently.- But here we are applying it to a tensor of shape
(B, T, C). The layer acts on all the input embeddings and sequences independently
- But here we are applying it to a tensor of shape
- The output of this FFN is
(B, T, C)
The only thing we have not mentioned is the use of Layer Normalization and Skip connections. These are typical tricks to improve training of networks. It will become more clear how they are used in the next section when we put it all together in the code.
![]()
Putting it all Together
from math import sqrt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from datasets import load_dataset
from tqdm import tqdm
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
class Config:
vocab_size = tokenizer.vocab_size
seq_length = 128 # will also denote as T i.e. "time dimension"
batch_size = 256 # will also denote as B
embed_dim = 64 # will also denote as C i.e. "channel dimension"
num_heads = 4
head_dim = embed_dim // num_heads # will also denote as H
dropout_prob = 0.0
num_transformer_layers = 4
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.token_embd = nn.Embedding(config.vocab_size, config.embed_dim)
self.pos_embd = nn.Embedding(config.seq_length, config.embed_dim)
self.dropout = nn.Dropout(config.dropout_prob)
self.layer_norm = nn.LayerNorm(config.embed_dim)
def forward(self, x):
# x is B,T --> the tensor of token input_ids
seq_length = x.size(-1)
token_embeddings = self.token_embd(x) # (B, T, C)
positional_embeddings = self.pos_embd(torch.arange(start=0, end=seq_length, step=1, device=device)) # (T, C)
x = token_embeddings + positional_embeddings # (B, T, C)
x = self.layer_norm(x) # (B, T, C)
x = self.dropout(x) # (B, T, C)
return x
class AttentionHead(nn.Module):
def __init__(self, config, mask=True):
super().__init__()
self.mask = mask
self.query = nn.Linear(config.embed_dim, config.head_dim, bias=False)
self.key = nn.Linear(config.embed_dim, config.head_dim, bias=False)
self.value = nn.Linear(config.embed_dim, config.head_dim, bias=False)
self.register_buffer("tril", torch.tril(torch.ones(config.seq_length, config.seq_length)))
self.dropout = nn.Dropout(config.dropout_prob)
def forward(self, x):
# x is (B, T, C)
b, t, c = x.shape
q = self.query(x) # (B, T, H)
k = self.key(x) # (B, T, H)
v = self.value(x) # (B, T, H)
dim_k = k.shape[-1] # i.e. head dimension
w = q @ k.transpose(-2, -1) / sqrt(dim_k) # (B, T, T)
if self.mask:
w = w.masked_fill(self.tril[:t, :t] == 0, float("-inf")) # (B, T, T)
w = F.softmax(w, dim=-1) # (B, T, T)
w = self.dropout(w) # good for regularization
out = w @ v # (B, T, H)
return out
class MultiHeadAttention(nn.Module):
def __init__(self, config, mask=True):
super().__init__()
self.attention_heads = nn.ModuleList([AttentionHead(config, mask) for _ in range(config.num_heads)])
self.linear_proj = nn.Linear(config.embed_dim, config.embed_dim)
def forward(self, x):
# each input tensor x has shape (B, T, C)
# each attention head, head(x) is of shape (B, T, H)
# concat these along the last dimension to get (B, T, C)
x = torch.concat([head(x) for head in self.attention_heads], dim=-1)
return self.linear_proj(x) # (B, T, C)
class FeedForwardNetwork(nn.Module):
def __init__(self, config):
super().__init__()
self.layer1 = nn.Linear(config.embed_dim, 4 * config.embed_dim)
self.layer2 = nn.Linear(4 * config.embed_dim, config.embed_dim)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.dropout_prob)
def forward(self, x):
# x is (B, T, C)
x = self.layer1(x) # (B, T, 4C)
x = self.gelu(x) # (B, T, 4C)
x = self.layer2(x) # (B, T, C)
x = self.dropout(x) # (B, T, C)
return x
class TransformerBlock(nn.Module):
def __init__(self, config, mask=True):
super().__init__()
self.mha = MultiHeadAttention(config, mask)
self.ffn = FeedForwardNetwork(config)
self.layer_norm_1 = nn.LayerNorm(config.embed_dim)
self.layer_norm_2 = nn.LayerNorm(config.embed_dim)
def forward(self, x):
# x is (B, T, C)
x = x + self.mha(self.layer_norm_1(x)) # (B, T, C)
x = x + self.ffn(self.layer_norm_2(x)) # (B, T, C)
return x
class Transformer(nn.Module):
def __init__(self, config, mask=True):
super().__init__()
self.embeddings = Embeddings(config)
self.transformer_layers = nn.ModuleList([TransformerBlock(config, mask) for _ in range(config.num_transformer_layers)])
def forward(self, x):
# x is shape (B, T). It is the output from a tokenizer
x = self.embeddings(x) # (B, T, C)
for layer in self.transformer_layers:
x = layer(x) # (B, T, C)
return x # (B, T, C)
- The inputs of shape
(B, T)can be passed through the transformer to produce a tensor of shape(B, T, C). - The final embeddings are "context" aware.
Transformer(Config).to(device)(inputs.to(device)).shape
Training Decoder For Next Token Prediction
- This code is meant to be a small "unit test" to see if we can train a simple model for next token prediction.
- It's not meant to be a "good" model, but something to refer to for educational purposes.
- We will use the dataset from the paper TinyStories: How Small Can Language Models Be and Still Speak Coherent English? [@eldan2023tinystories].
- Split the dataset into chunks where the input is the sequence of tokens of shape
(B, T). - The corresponding target tensor is of shape
(B, T)and is the input sequence, right shifted. - Add a classifier layer to the transformer decoder to predict the next token from the vocabulary.
dataset = load_dataset("roneneldan/TinyStories")["train"]
dataset = dataset.select(range(500000)) # decrease/increase to fewer data points to speed up training
def tokenize(element):
# Increase max_length by 1 to get the next token
outputs = tokenizer(
element["text"],
truncation=True,
max_length=Config.seq_length + 1,
padding="max_length",
return_overflowing_tokens=True,
return_length=True,
add_special_tokens=False,
)
input_batch = []
target_batch = []
for length, input_ids in zip(outputs["length"], outputs["input_ids"]):
if length == Config.seq_length + 1:
input_batch.append(input_ids[:-1]) # Exclude the last token for input
target_batch.append(input_ids[1:]) # Exclude the first token for target
return {"input_ids": input_batch, "labels": target_batch}
tokenized_datasets = dataset.map(tokenize, batched=True, remove_columns=dataset.column_names, num_proc=8)
print(tokenizer.convert_ids_to_tokens(tokenized_datasets[0]["input_ids"]))
print(tokenizer.convert_ids_to_tokens(tokenized_datasets[0]["labels"]))
class LanguageModel(nn.Module):
def __init__(self, config):
super().__init__()
self.transformer = Transformer(config, mask=True)
self.classifier = nn.Linear(config.embed_dim, tokenizer.vocab_size)
def forward(self, x):
# x is (B, T) the token ids
x = self.transformer(x) # (B, T, C)
logits = self.classifier(x) # (B, T, V)
return logits
model = LanguageModel(Config).to(device)
print(sum(p.numel() for p in model.parameters()) / 1e6, "M parameters")
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
def generate_text(prompt, max_tokens=100):
inputs = tokenizer(
[prompt],
truncation=True,
max_length=Config.seq_length,
add_special_tokens=False,
)
inputs = torch.tensor(inputs.input_ids).to(device)
for i in range(max_tokens):
logits = model(inputs) # (B, T, V)
# convert logits to probabilities and only consider the probabilities for the last token in the sequence i.e. predict next token
probs = logits[:, -1, :].softmax(dim=-1)
# sample a token from the distribution over the vocabulary
idx_next = torch.multinomial(probs, num_samples=1)
inputs = torch.cat([inputs, idx_next], dim=1)
return tokenizer.decode(inputs[0])
Since we have not trained the model yet this output should be complete random garbage tokens.
print(generate_text("Once upon"))
- This diagram helps me understand how the input sequences and the target sequences (right shifted) are used during training

for epoch in range(1):
train_loss = []
loop = tqdm(range(0, len(tokenized_datasets), Config.batch_size))
for i in loop:
x = torch.tensor(tokenized_datasets[i : i + Config.batch_size]["input_ids"]).to(device) # (B, T)
target = torch.tensor(tokenized_datasets[i : i + Config.batch_size]["labels"]).to(device) # (B, T)
logits = model(x) # (B, T, V)
b, t, v = logits.size()
logits = logits.view(b * t, v) # (B*T, V)
target = target.view(b * t) # B*T
loss = F.cross_entropy(logits, target)
train_loss.append(loss.item())
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
if i % 1000 == 0:
avg_loss = np.mean(train_loss)
train_loss = []
loop.set_description(f"Epoch {epoch}, Avg Loss: {avg_loss:.4f}")
- Let's try generating text with the trained model now:
print(generate_text("Once upon"))
Not quite GPT-4 performance, lol!