China AI Labs - Model Releases - 2025-01
Intro
The Chinese labs, DeepSeek and Alibaba’s Qwen, are releasing a lot of models. I wanted to quickly write down some notes so I can keep it all straight in my head.
DeepSeek
DeepSeek-R1
- Github - DeepSeek-R1
- Paper
- I use the DeepSeek Chat Platform to use it. The API platform is really good too!
- Trained via large-scale reinforcement learning (RL)
- Uses DeepSeek-V3-Base as the base model and then employs GRPO as the RL framework.
- What emerges first is DeepSeek-R1-Zero
- generates lots of chain of thought
- first open source research to show LLMs can develop reasoning capabilities purely through RL, without the need for SFT
- But has issues for practical use cases (poor readability, language mixing)
- Pipeline to develop DeepSeek-R1 using RL and SFT
- collect small amount of COT data for cold-start
- fine-tune DeepSeek-V3-Base on cold-start data
- apply RL just as in DeepSeek-R1-Zero
- apply SFT on top of RL
- This is the model we should use for practical use cases
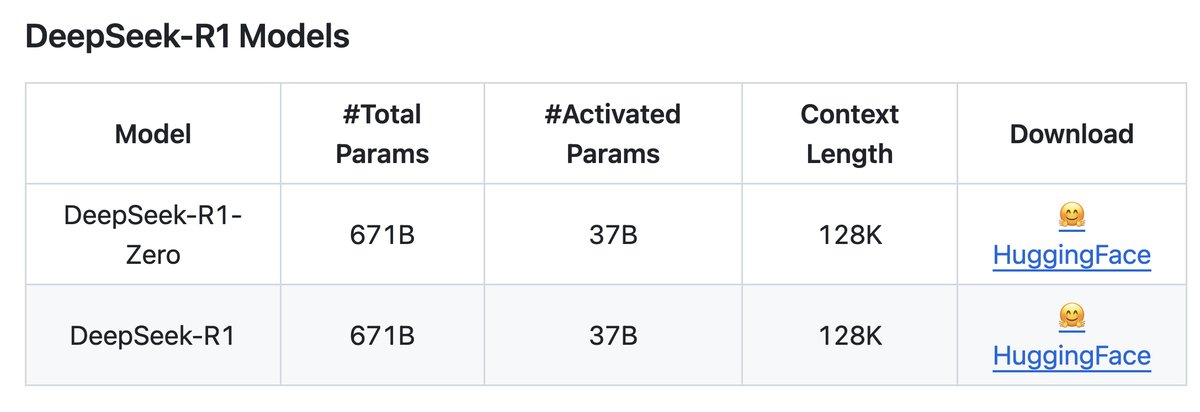
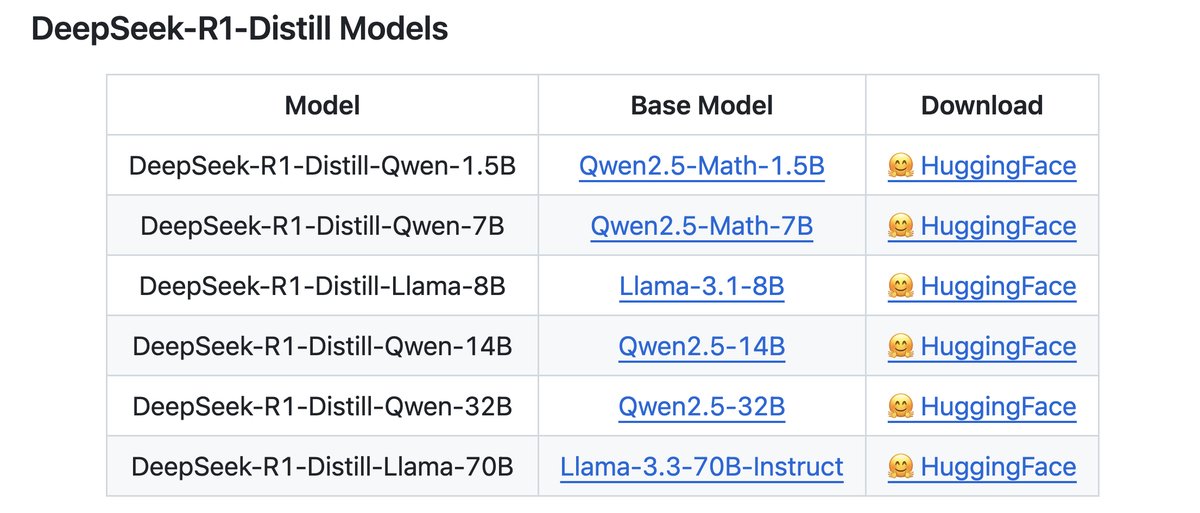
- Distilled Models
- DeepSeek-R1 is the teacher model to generate 800K training samples
- fine-tune several smaller dense models using Qwen and Llama
- Blog post from Philipp Schmid -Mini-R1: Reproduce Deepseek R1 "aha moment“ a RL tutorial
- Good Tweet Summary here from Philipp Schmid

- The smaller distilled versions can be run locally through ollama for example --->
ollama run deepseek-r1. - Also check out the-illustrated-deepseek-r1 blog post
Janus-Pro
Running on Modal
Let's create some endpoints with Modal to serve the 7B model. That's the thing I love about Modal. I can just copy/paste the inference code from the repo and it just works.
from io import BytesIO
import requests
from IPython.display import display
from janus_endpoint_inference import text_and_image_to_text, text_to_image
from PIL import Image
image_url = "https://fastly.picsum.photos/id/37/2000/1333.jpg?hmac=vpYLNsQZwU2szsZc4Uo17cW786vR0GEUVq4icaKopQI"
response = requests.get(image_url)
img = Image.open(BytesIO(response.content))
display(img)
Here we send the above image to our deployed endpoint and ask it to describe the image.
desc = text_and_image_to_text(image_url, "Give me a description of the image")
print(desc)
Next we take a prompt and send it to the other endpoint we created for text to image.
prompt = "Serene coastal scene with lush green foliage and red flowers in the foreground, ocean stretching to the horizon under a cloudy sky, rocky outcrop on the right, calm and peaceful atmosphere, natural and untouched beauty, highly detailed and realistic."
for img in text_to_image(prompt):
display(img)
I still think even flux-dev is better. I wrote about deploying flux to Modal in a previous post.
Qwen
The Qwen team has also been shipping to start the year off strong!
Qwen2.5 VL
I really loved Qwen2-VL and wrote about it previously here. Now we get an updated model!
- blog post
- repo
- model comes in three sizes: 3B, 7B, and 72B
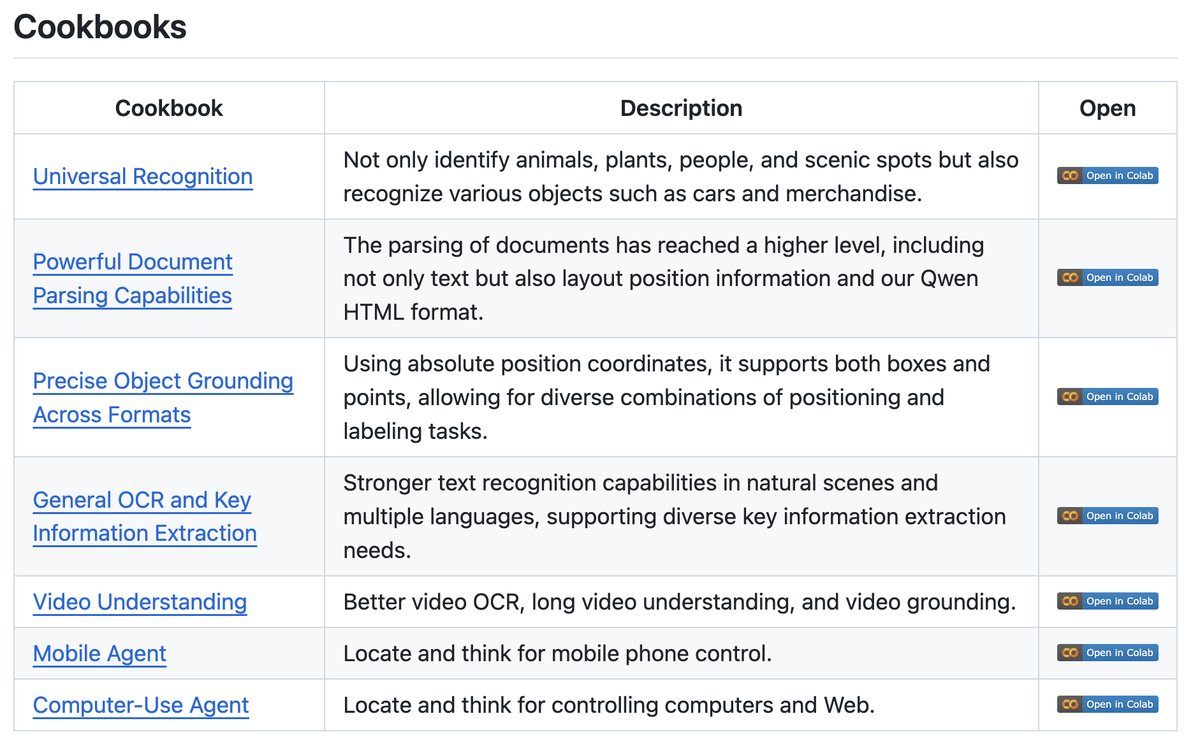
- It sounds awesome. Check out these key points directly from the blog post:

- Okay, Qwen2.5 VL looks insanely feature rich. TBH, it deserves its own blog post.
Qwen2.5-1M
Qwen2.5-Max
Conclusion
I just wanted to write out some of these different models on one page. The DeepSeek-R1 model is really awesome. I have a lot to learn about the RL recipes. When it comes to the other models, I'm mostly excited about the Qwen2.5-VL model. Once I saw the different cookbook recipes for it, I suddenly realized it needs a separate blog post. I want to deploy it on Modal and create endpoints for all of its capabilities. I don't think I will bother with DeepSeek Janus-Pro.