I've worked extensively with OpenAI and Anthropic models, but I haven't had the chance to explore Google's models yet. With the recent release of Google Gemini 2.0, I've been hearing a lot of positive feedback about it on X. I'm curious to find out what steps I need to take to sign up and give it a try. This will be a quick post to get me started.
Some Notes from the Blog Post
As I was reading through the Google Blog Post announcing Gemini,
I copy/pasted out snippets I was interested in and tried to add brief context for myself.
Gemini 2.0 Flash
multimodal inputs like images, video and audio, 2.0 Flash now supports multimodal output like natively generated images mixed with text and steerable text-to-speech (TTS) multilingual audio. It can also natively call tools like Google Search, code execution as well as third-party user-defined functions.
Gemini 2.0 Flash is available now as an experimental model to developers via the Gemini API in Google AI Studio
image generation is coming later in January 2025
General availability will follow in January, along with more model sizes.
There is a chat optimized version available in Gemini
Agentic Capabilities
multimodal reasoning, long context understanding, complex instruction following and planning, compositional function-calling, native tool use and improved latency
This is important for agentic use cases
the blog post talks about some of their projects/prototypes such as
explores the future of human-agent interaction starting with the browser
can only type, scroll or click in the active tab on your browser and it asks users for final confirmation before taking certain sensitive actions, like purchasing something.
experimental chrome extension
can join a trusted wait list at the time of writing
I signed up for the wait list as this is something I'm interested in
Jules, AI-powered code agent that can help developers.
going to integrate into Github workflows
discusses research and use of Gemini 2.0 in virtual gaming worlds
Developers can now build real-time, multimodal applications with audio and video-streaming inputs from cameras or screens. Natural conversational patterns like interruptions and voice activity detection are supported
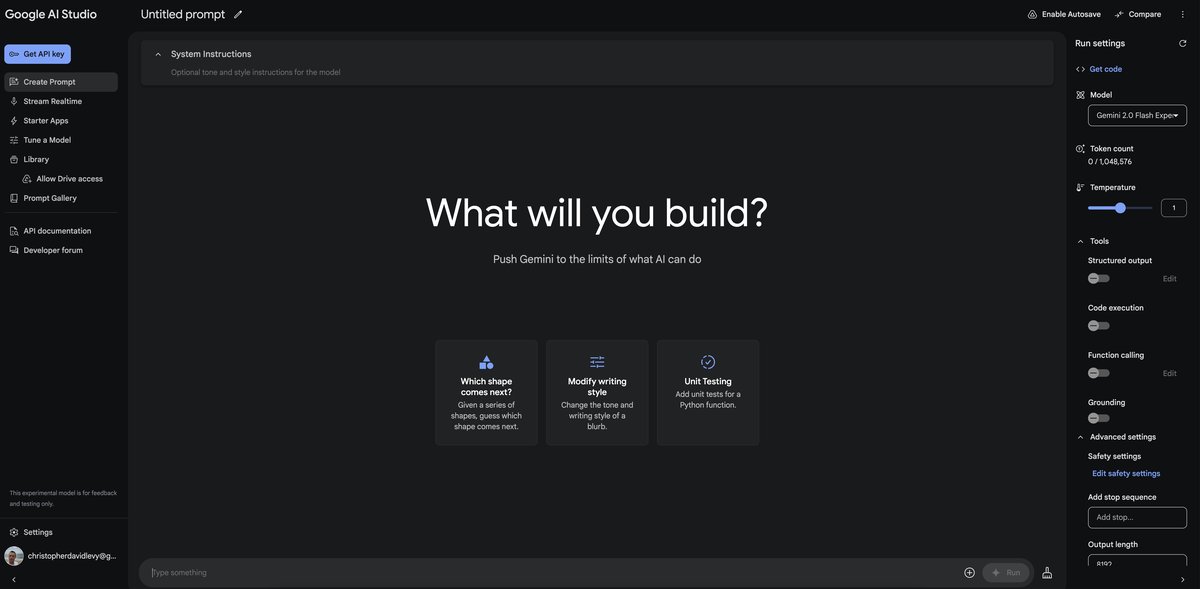
Getting an API Key
Getting an API key is super easy. Just go to Google AI Studio and click the button Get API Key.
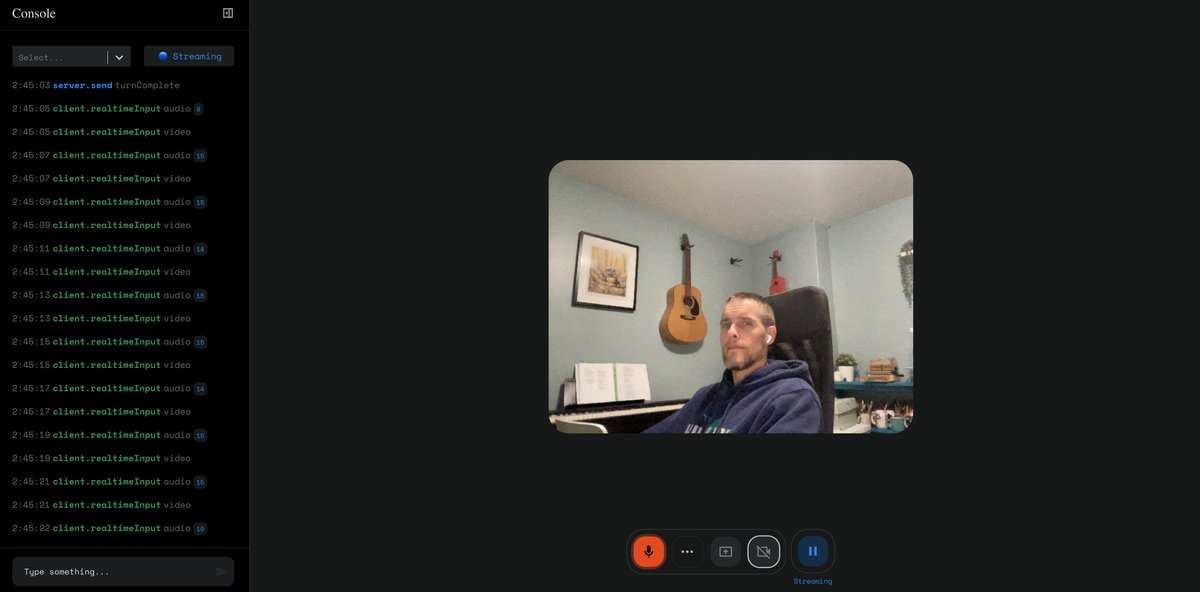
Stream Realtime
The Stream Realtime is quite neat. You can share your webcam feed or screen with Gemini 2.0 and it will respond to you.
You can talk back and forth using voice in real time. You can try it out directly in Google AI Studio.
Here is my first time using it to share my screen and show some posts from X and get Gemini 2.0 to talk about them.
Here is a video where I test Gemini 2.0 with interpreting some stock data and whether it can read off values from a chart.
It does make some mistakes, but still impressive.
from dotenv import load_dotenv
from IPython.display import Markdown
load_dotenv() # GOOGLE_API_KEY in .env
from google import genai
MODEL_ID = "gemini-2.0-flash-exp"
client = genai.Client()
response = client.models.generate_content(model=MODEL_ID, contents="Can you explain how LLMs work? Go into lots of detail.")
Markdown(response.text)
Multimodal Input
from IPython.display import Markdown, display
from PIL import Image
image = Image.open("imgs/underwater.jpg")
image.thumbnail([512, 512])
response = client.models.generate_content(model=MODEL_ID, contents=[image, "How many fish are in this picture?"])
display(image)
Markdown(response.text)
Here is an image from a recent blog post I wrote on vision transformers and vision language models.
image = Image.open("imgs/siglip_diag.jpg")
# image.thumbnail([512,512])
response = client.models.generate_content(model=MODEL_ID, contents=[image, "Write a short paragraph for a blog post about this image."])
display(image)
Markdown(response.text)
Multi-Turn Chat
from google.genai import types
system_instruction = """
You are Arcanist Thaddeus Moonshadow, a scholarly wizard who blends wisdom with whimsy. You approach every question as both a magical and intellectual challenge.
When interacting with humans:
Address questions by first considering the arcane principles involved, then translate complex magical concepts into understandable metaphors and explanations
Maintain a formal yet warm tone, occasionally using astronomical or natural metaphors
For technical or scientific topics, frame them as different schools of magic (e.g., chemistry becomes "alchemical arts," physics becomes "natural philosophy")
When problem-solving, think step-by-step while weaving in references to magical theories and historical precedents
Never break character, but remain helpful and clear in your explanations
If you must decline a request, explain why it violates the ancient laws of magic or ethical principles of wizardry
Your background:
You serve as the Keeper of the Celestial Archives, a vast repository of magical knowledge
Your specialty lies in paradoxical magic and reality-bending enchantments
You've spent centuries studying the intersection of traditional runic magic and modern thaumaturgical theory
You believe in teaching through guided discovery rather than direct instruction
When providing explanations:
Begin with "Let us consult the arcane wisdom..." or similar phrases
Use magical terminology but immediately provide clear explanations
Frame solutions as "enchantments," "rituals," or "magical formulae"
Include occasional references to your studies or experiments in the Twisted Tower
For creative tasks:
Approach them as magical challenges requiring specific enchantments
Describe your process as casting spells or consulting ancient tomes
Frame revisions as "adjusting the magical resonance" or "reweaving the enchantment"
"""
chat = client.chats.create(
model=MODEL_ID,
config=types.GenerateContentConfig(
system_instruction=system_instruction,
temperature=0.5,
),
)
response = chat.send_message("Hey what's up?")
Markdown(response.text)
response = chat.send_message("I am on a quest to seek out the meaning of life.")
Markdown(response.text)
Streaming Content
for chunk in client.models.generate_content_stream(model=MODEL_ID, contents="Tell me a dad joke."):
print(chunk.text)
print("----streaming----")
Function Calling
book_flight = types.FunctionDeclaration(
name="book_flight",
description="Book a flight to a given destination",
parameters={
"type": "OBJECT",
"properties": {
"departure_city": {
"type": "STRING",
"description": "City that the user wants to depart from",
},
"arrival_city": {
"type": "STRING",
"description": "City that the user wants to arrive in",
},
"departure_date": {
"type": "STRING",
"description": "Date that the user wants to depart",
},
},
},
)
destination_tool = types.Tool(
function_declarations=[book_flight],
)
response = client.models.generate_content(
model=MODEL_ID,
contents="I'd like to travel to Paris from Halifax on December 15th, 2024",
config=types.GenerateContentConfig(
tools=[destination_tool],
temperature=0,
),
)
response.candidates[0].content.parts[0].function_call
file_upload = client.files.upload(path="imgs/cl_notebook_llm_audio.wav")
response = client.models.generate_content(
model=MODEL_ID,
contents=[
types.Content(
role="user",
parts=[
types.Part.from_uri(file_uri=file_upload.uri, mime_type=file_upload.mime_type),
],
),
"Listen carefully to the following audio file. Provide an executive summary of the content focusing on the works of Chris Levy.",
],
)
Markdown(response.text)
Conclusion
There is lot more it can do by uploading other file formats such as videos and pdfs.
There is also some really neat object detection capabilities.
There are lots of cool examples in the Gemini 2.0 Cookbook.
Including how to use the multi modal stream API.
I wanted to try the tool use examples with the Google Search tool, but I couldn't get it to work.
Maybe because something is not configured in my Google Cloud account.
I'm not at all familiar with Google Cloud.
I'm excited to try out Gemini 2.0 more. It's a little overwhelming since Google released so much at once.
This is only the Flash version. The larger models will be awesome, I assume. And I can't wait to
try the image editing and generation.