Intro to LLMs
Lunch and Learn Talk
import os
from dotenv import load_dotenv
load_dotenv()
ENV Setup {.smaller}
- create a virtual env
python3 -m venv env
source env/bin/activate
- install packages
pip install tiktoken
pip install openai
pip install instructor
pip install transformers
pip install torch
pip install python-dotenv
pip install notebook
- add env vars in .env file
OPENAI_API_KEY=<key>
TOGETHER_API_KEY=<key>
Background
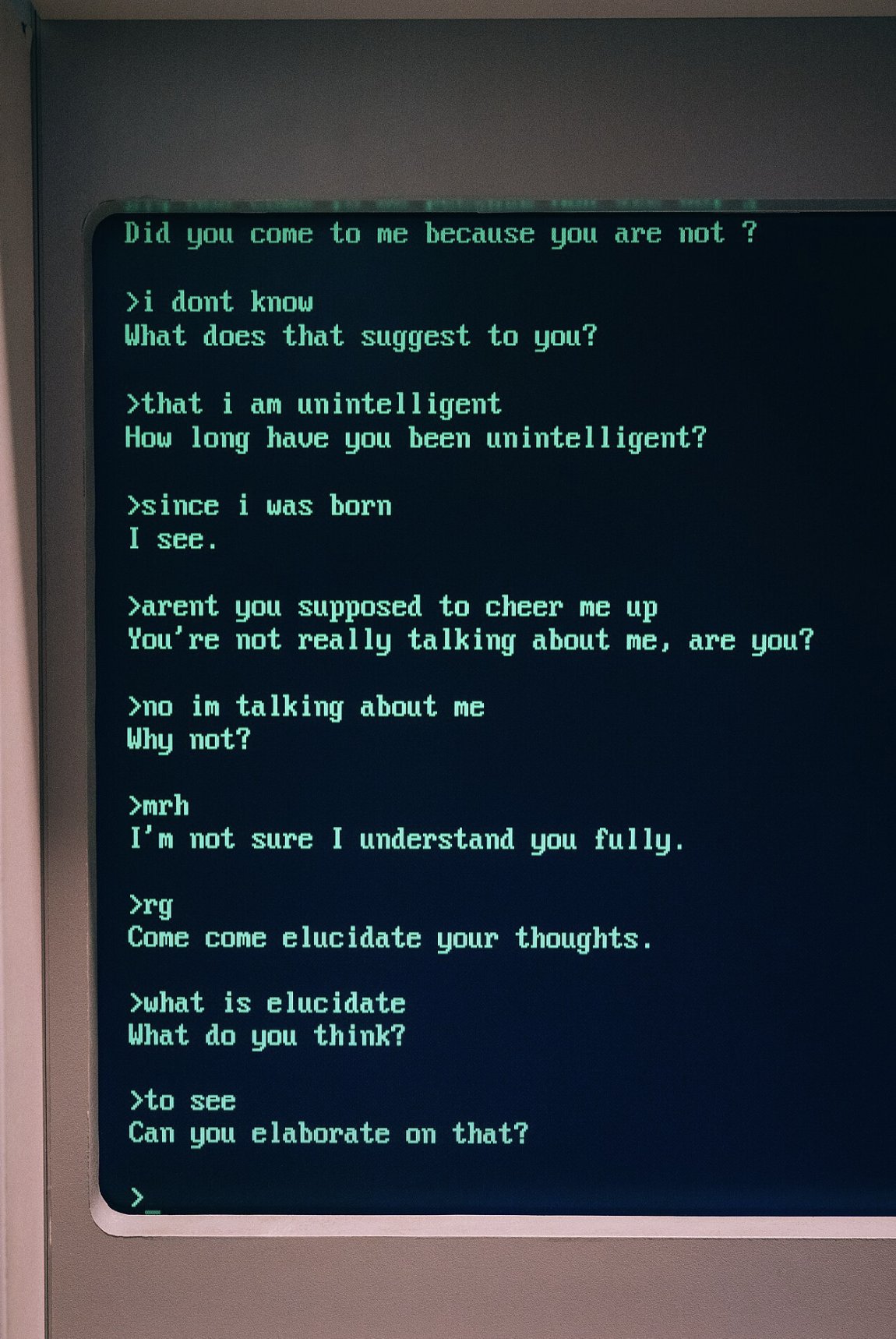
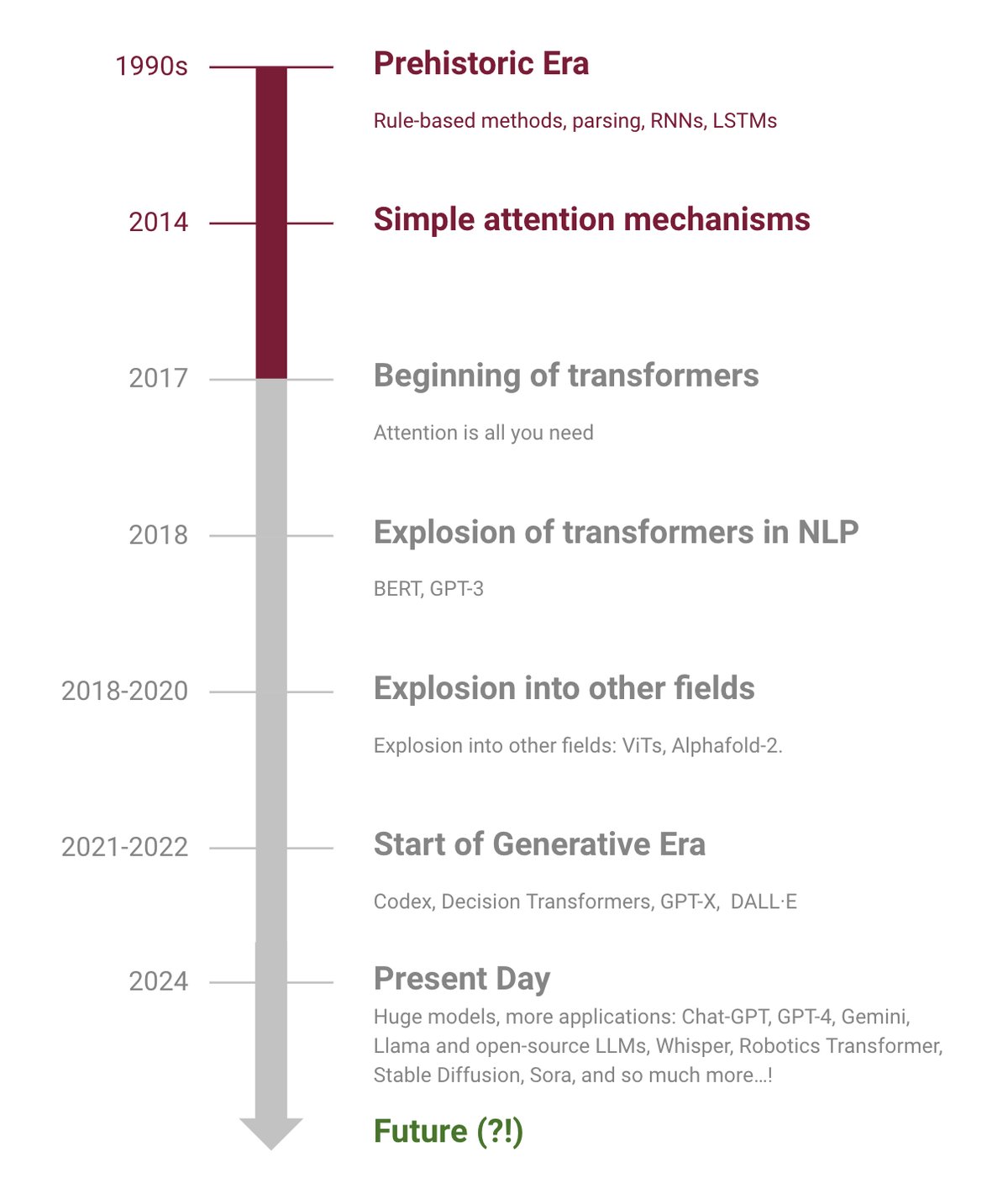
NLP Through The Years {.smaller}
:::: {.columns}
::: {.column width="50%"}
 {height=20%, width=80%}
{height=20%, width=80%}
:::
::: {.column width="50%"}
 {height=60%, width=80%}
:::
{height=60%, width=80%}
:::
::::
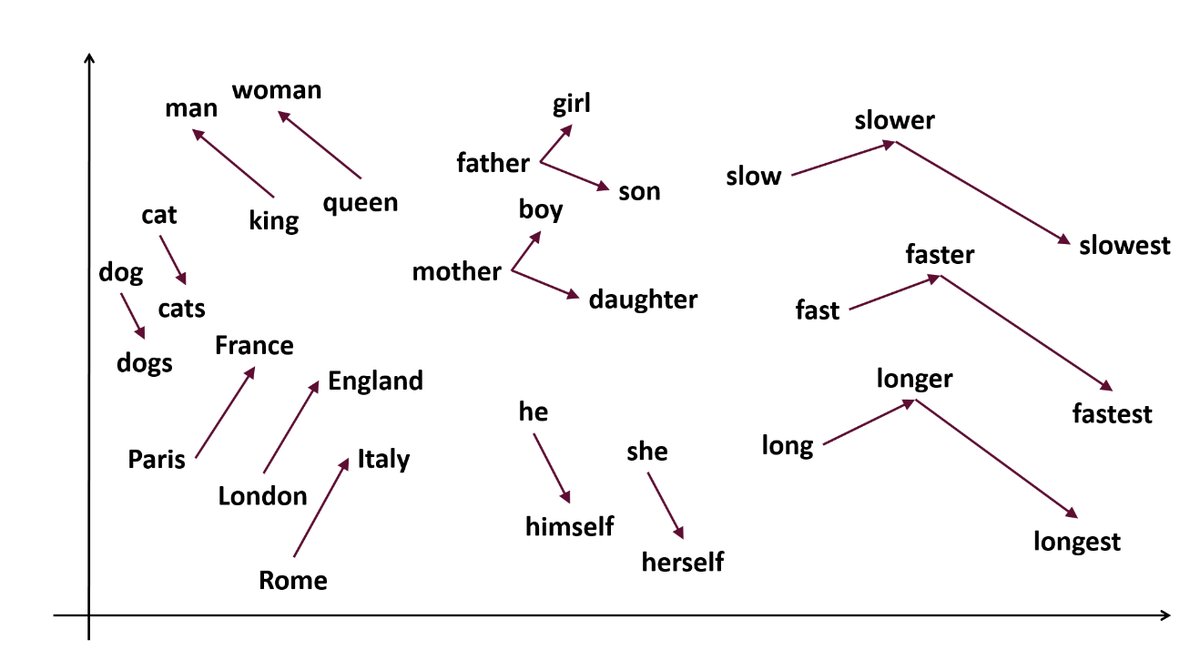
Word Embeddings {.smaller}
- represent each word as an embedding (vector of numbers)
- useful computations such as distance (cosine/euclidean)
- mapping of words onto a semantic space
- example: Word2Vec (2013), GloVe, BERT, ELMo
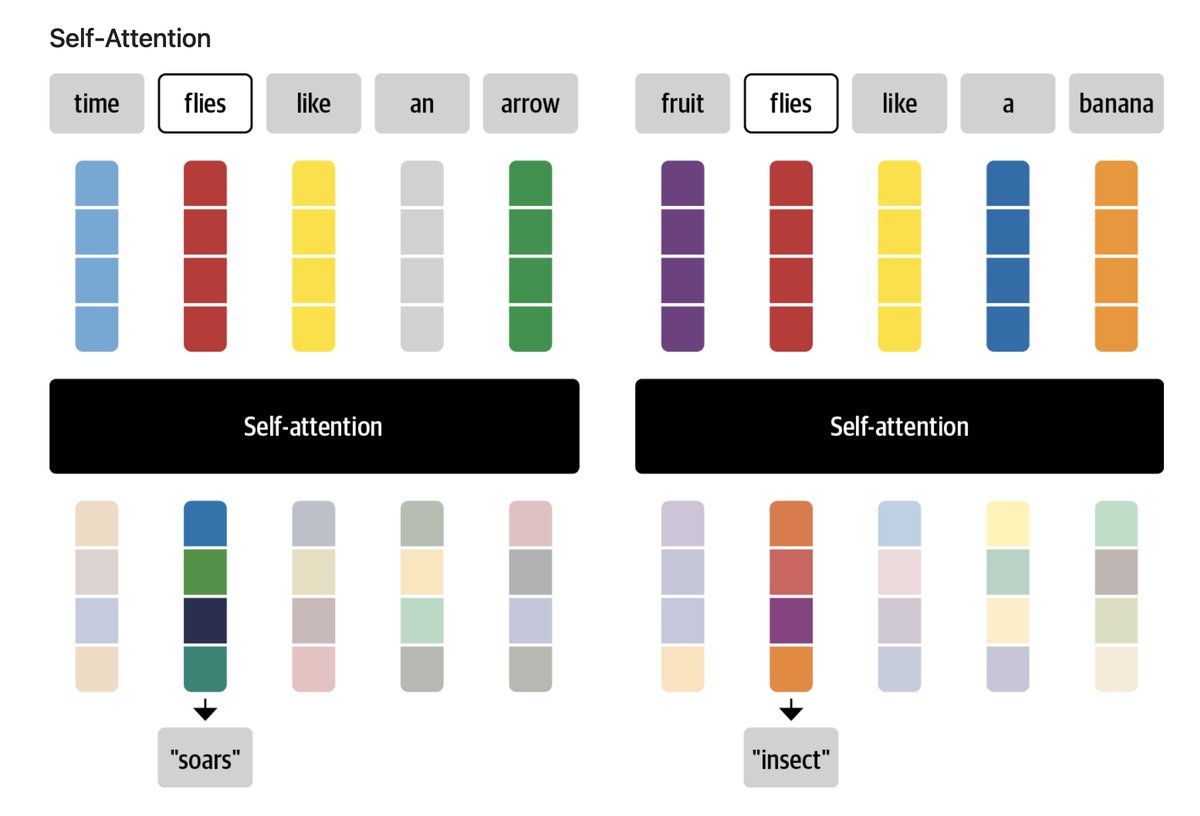
Attention and Transformers
 {height=60%,width=60%}
{height=60%,width=60%}
Transformer & Multi-Head Attention
:::: {.columns}
::: {.column width="50%"}
![]() {height=70%, width=70%}
:::
{height=70%, width=70%}
:::
::: {.column width="50%"}
![]() :::
:::
::::
What is a LLM (large language model)?
- LLMs are scaled up versions of the Transformer architecture (millions/billions of parameters)
- Most modern LLMs are decoder only transformers
- Trained on massive amounts of “general” textual data
- Training objective is typically “next token prediction”: P(Wt+1|Wt,Wt-1,...,W1)
Next Token Prediction
- LLMs are next token predictors
- "It is raining today, so I will take my _______."


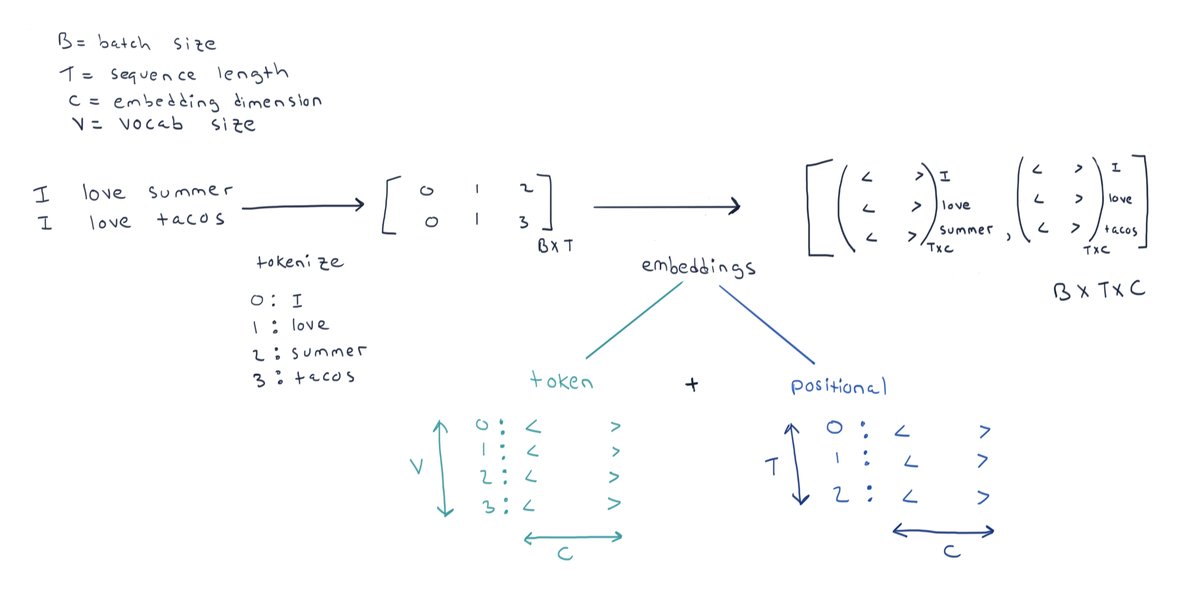
Tokenization with tiktoken library {.smaller}
- The first step is to convert the input text into tokens
- Each token has an id in the vocabulary
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4-0125")
encoded_text = enc.encode("tiktoken is great!")
encoded_text
[enc.decode([token]) for token in encoded_text]
enc.decode([83, 1609, 5963, 374, 2294, 0])
Tokenization with transformers library {.smaller}
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
texts = [
"I love summer",
"I love tacos",
]
inputs = tokenizer(
texts,
return_tensors="pt",
padding="max_length",
max_length=16,
truncation=True,
).input_ids
print(inputs)
print(inputs.shape) # (B, T)
print(tokenizer.vocab_size)
for row in inputs:
print(tokenizer.convert_ids_to_tokens(row))
Tokenization is the First Step {.smaller}
LLMS are not great at math. Why? {.smaller}
- because of tokenization and next token prediction
What is the average of: 2009 1746 4824 8439
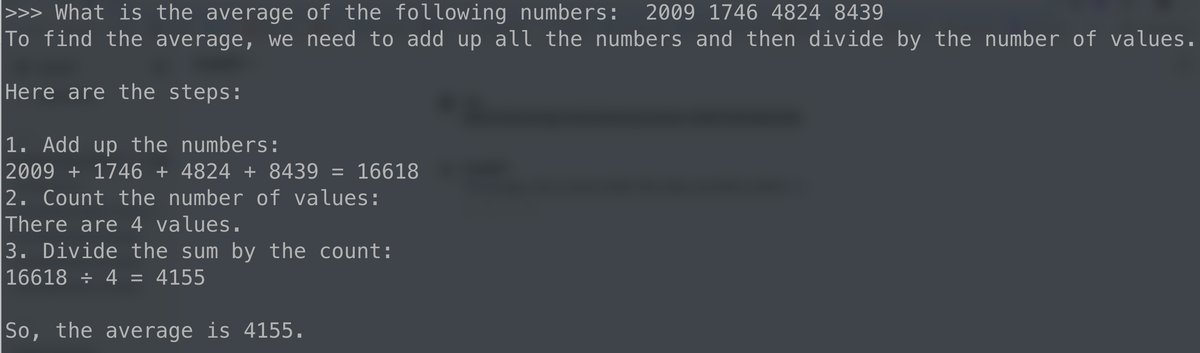
encoded_text = enc.encode("What is the average of: 2009 1746 4824 8439")
print(encoded_text)
print([enc.decode([token]) for token in encoded_text])
Basic Transformer Architecture - Futher Reading {.smaller}
- Lots of resources online
- Some of the ones I enjoyed while learning:
- Chapter 3 of the book Natural Language Processing With Transformers
- Andrej Karpathy's video Let's build GPT: from scratch, in code, spelled out
- Sebastian Raschka's Blog Post Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs
- Omar Sanseviero's Blog Post The Random Transformer
- The Illustrated Transformer
- The original paper: Attention Is All You Need
Instruction Models
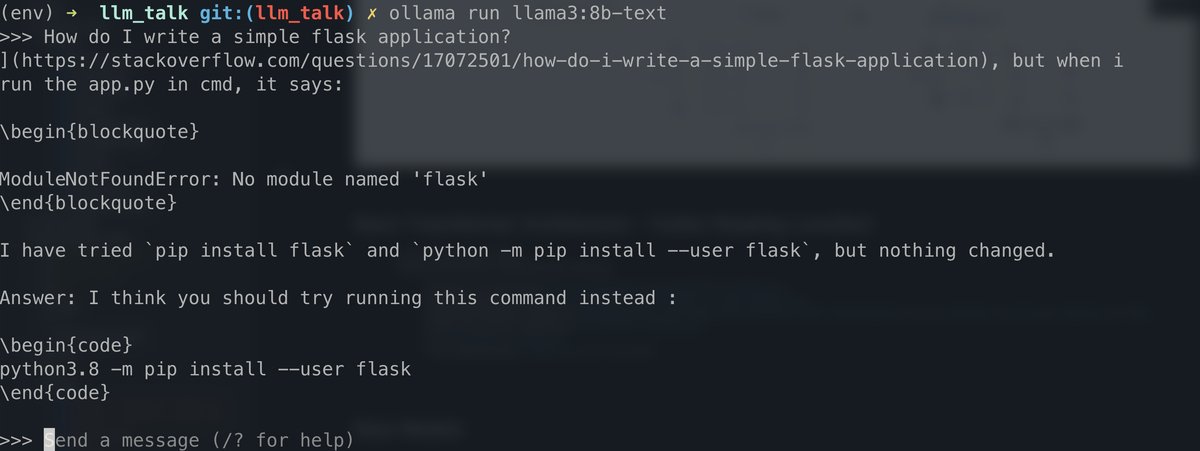
Base Models VS Instruct Models {.smaller}
meta-llama/Meta-Llama-3-8B(base model)
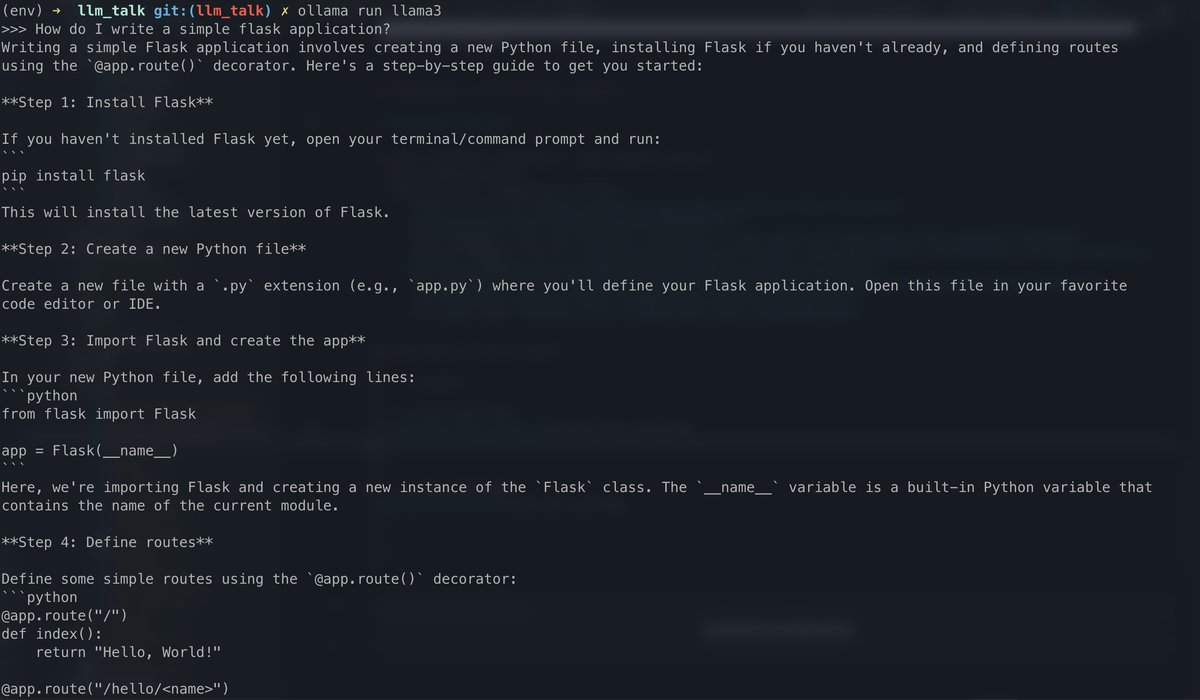
Base Models VS Instruct Models {.smaller}
meta-llama/Meta-Llama-3-8B-Instruct
Popular Instruction Fine-Tuned LLMs {.smaller}
- closed
- open
- Meta:
Llama-3-8B-Instruct,Llama-3-70B-Instruct - Mistral:
Mistral 7B,Mixtral 8x7B,Mixtral 8x22B - Qwen:
Qwen-1.8B,Qwen-7B,Qwen-14B,Qwen-72B - HuggingFace:
Zephyr-ORPO-141b-A35b-v0.1 - Databricks:
DBRX-Instruct-Preview - NousResearch:
Hermes-2-Pro-Mistral-7B, - Cohere:
Command R+
- Meta:
The Gap is closing {.smaller}
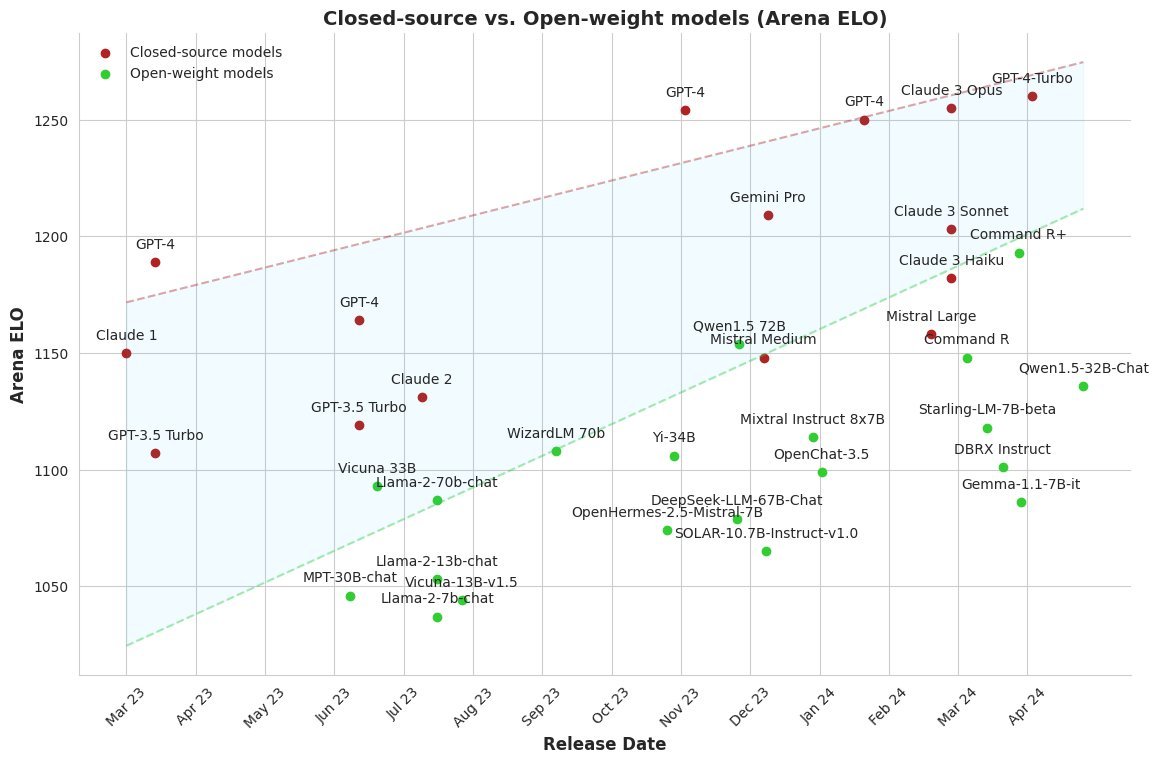
Aligning language models
- There is so much theory/research behind creating instruction models
- Not going to cover that here
- Checkout this recent talk, Aligning open language models, from Nathan Lambert
- State of GPT Keynote By Andrej Karpathy
- Large Language Model Course by Maxime Labonne
OpenAI Compatible LLM Inference
OpenAI Compatible LLM Inference
import openai
client = openai.OpenAI()
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[
{"role": "user", "content": "Who are the main characters from Lord of the Rings?."},
],
)
response = chat_completion.choices[0].message.content
print(response)
OpenAI Compatible LLM Inference
import openai
client = openai.OpenAI(api_key=os.environ.get("TOGETHER_API_KEY"), base_url="https://api.together.xyz/v1")
chat_completion = client.chat.completions.create(
model="META-LLAMA/LLAMA-3-70B-CHAT-HF",
messages=[
{"role": "user", "content": "Who are the main characters from Lord of the Rings?."},
],
)
response = chat_completion.choices[0].message.content
print(response)
OpenAI Compatible LLM Inference {.smaller}
import openai
client = openai.OpenAI(api_key=os.environ.get("TOGETHER_API_KEY"), base_url="https://api.together.xyz/v1")
chat_completion = client.chat.completions.create(
model="META-LLAMA/LLAMA-3-70B-CHAT-HF",
messages=[
{"role": "user", "content": "Who are the main characters from Lord of the Rings?."},
],
)
response = chat_completion.choices[0].message.content
print(response)
OpenAI Compatible LLM Inference {.smaller}
- local inference with ollama
import openai
client = openai.OpenAI(api_key="ollama", base_url="http://localhost:11434/v1")
chat_completion = client.chat.completions.create(
model="llama3",
messages=[
{"role": "user", "content": "Who are the main characters from Lord of the Rings?."},
],
)
response = chat_completion.choices[0].message.content
print(response)
Chat Templates {.smaller}
from transformers import AutoTokenizer
checkpoint = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- Each model has its own expected input format. For Llama3 it's this:
"""
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a friendly chatbot who always responds in the style of a pirate<|eot_id|><|start_header_id|>user<|end_header_id|>
How many helicopters can a human eat in one sitting?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
- With chat templates we can use this familiar standard:
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
Structured Output
Structured Output {.smaller}
import openai
client = openai.OpenAI()
chat_completion = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[
{
"role": "user",
"content": "Who are the main characters from Lord of the Rings?. "
"For each character give the name, race, "
"favorite food, skills, weapons, and a fun fact.",
},
],
)
response = chat_completion.choices[0].message.content
print(response)
Structured Output {.smaller}
- JSON mode and Function Calling give us structured output
- instructor - library - "Pydantic is all you need"
import instructor
import openai
from pydantic import BaseModel
client = instructor.from_openai(openai.OpenAI())
# Define your desired output structure
class UserInfo(BaseModel):
name: str
age: int
# Extract structured data from natural language
user_info = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
response_model=UserInfo,
messages=[{"role": "user", "content": "Chris is 38 years old."}],
)
print(user_info.model_dump())
print(user_info.name)
print(user_info.age)
Structured Output {.smaller}
from typing import List
import instructor
import openai
from pydantic import BaseModel, field_validator
client = instructor.from_openai(openai.OpenAI())
class Character(BaseModel):
name: str
race: str
fun_fact: str
favorite_food: str
skills: List[str]
weapons: List[str]
class Characters(BaseModel):
characters: List[Character]
@field_validator("characters")
@classmethod
def validate_characters(cls, v):
if len(v) < 10:
raise ValueError(f"The number of characters must be at least 10, but it is {len(v)}")
return v
response = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[
{
"role": "user",
"content": "Who are the main characters from Lord of the Rings?. "
"For each character give the name, race, "
"favorite food, skills, weapons, and a fun fact. Give me at least 10 different characters.",
},
],
response_model=Characters,
max_retries=4,
)
from pprint import pprint
pprint(response.model_dump())
Function Calling {.smaller}
tools = [
{
"type": "function",
"function": {
"name": "get_weather_forecast",
"description": "Provides a weather forecast for a given location and date.",
"parameters": {
"type": "object",
"properties": {"location": {"type": "string"}, "date": {"type": "string"}},
"required": ["location", "date"],
},
},
},
{
"type": "function",
"function": {
"name": "book_flight",
"description": "Book a flight.",
"parameters": {
"type": "object",
"properties": {
"departure_city": {"type": "string"},
"arrival_city": {"type": "string"},
"departure_date": {"type": "string"},
"return_date": {"type": "string"},
"num_passengers": {"type": "integer"},
"cabin_class": {"type": "string"},
},
"required": [
"departure_city",
"arrival_city",
"departure_date",
"return_date",
"num_passengers",
"cabin_class",
],
},
},
},
{
"type": "function",
"function": {
"name": "send_slack_message",
"description": "Send a slack message to specific channel.",
"parameters": {
"type": "object",
"properties": {"channel_name": {"type": "string"}, "message": {"type": "string"}},
"required": ["channel_name", "message"],
},
},
},
]
import json
from datetime import date
import openai
client = openai.OpenAI()
chat_completion = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": f"Today's date is {date.today()}"},
{
"role": "user",
"content": """This coming Friday I need to book a flight from Halifax, NS to Austin, Texas.
It will be me and my friend and we need first class seats.
We will come back on Sunday. Let me know what I should pack for clothes
according to the weather there each day. Also please remind my team on
the DEV slack channel that I will be out of office on Friday.
1. Book the flight.
2. Let me know the weather.
3. Send the slack message.""",
},
],
tools=tools,
)
for tool in chat_completion.choices[0].message.tool_calls:
print(f"function name: {tool.function.name}")
print(f"function arguments: {json.loads(tool.function.arguments)}")
print()
RAG: Retrieval Augmented Generation {.smaller}
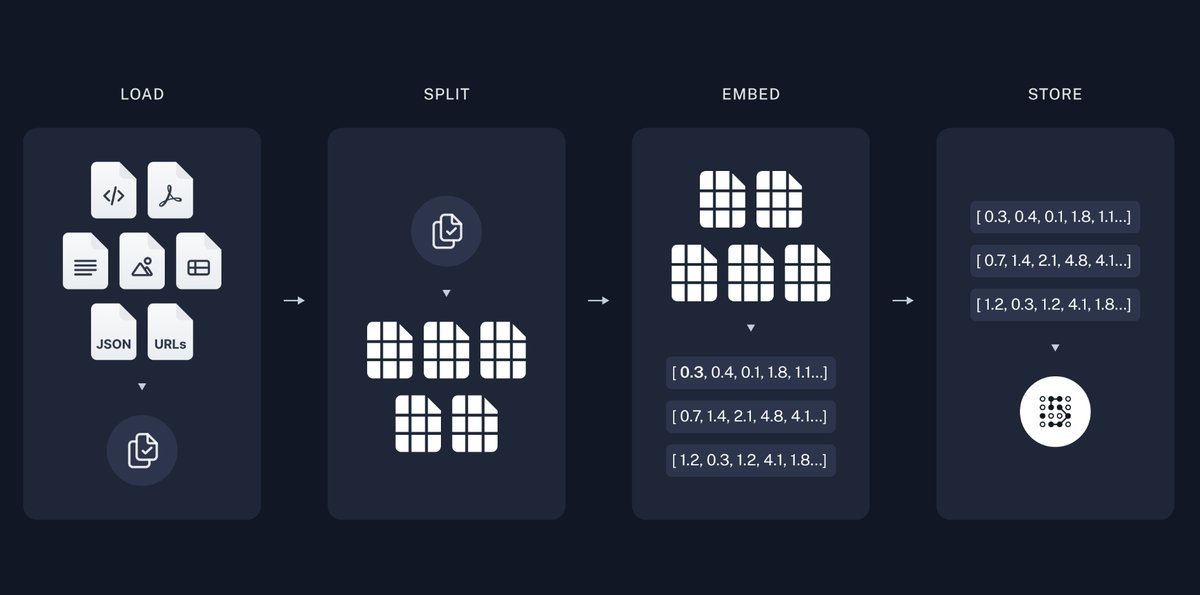
RAG: Step 1 - Index your Documents {.smaller}
- RAG is a technique for augmenting LLM knowledge with additional data.
- image source: langchain docs
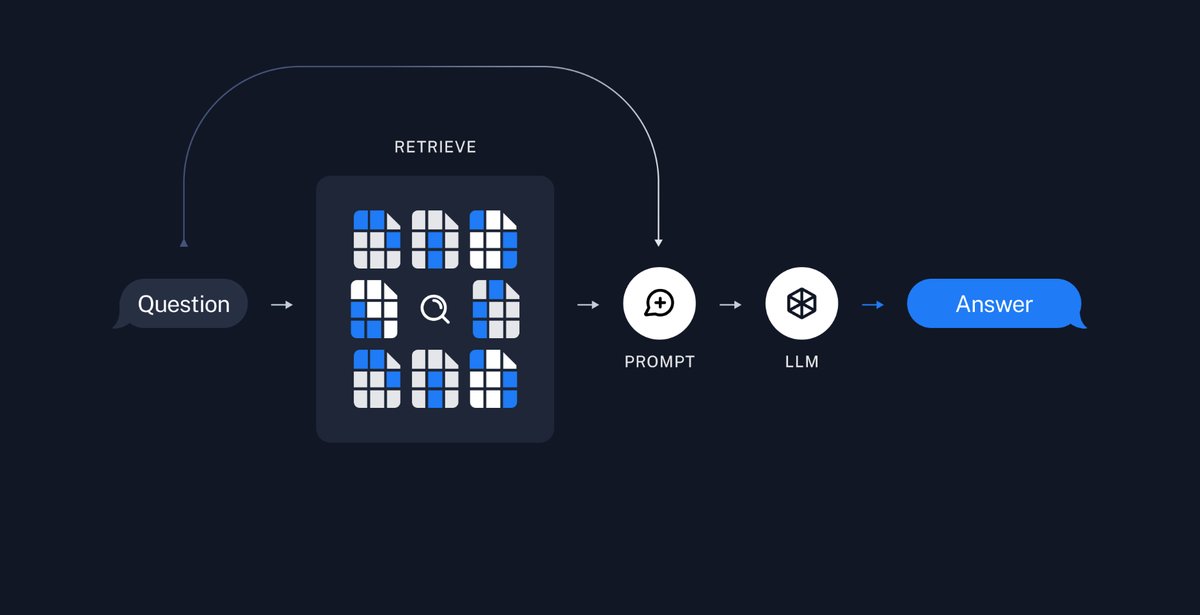
RAG: Step 2 - Query and Prompt LLM
 {height=60%, width=60%}
{height=60%, width=60%}
RAG Resources
-
Vector DBs
-
LLM Frameworks: (not necessary for building on prod but good for learning and POC)
MultiModal
MultiModal {.smaller}

MultiModal {.smaller}
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What is unusual about this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://i.pinimg.com/736x/6e/71/0d/6e710de5084379ba6a57b77e6579084f.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
MultiModal {.smaller}

MultiModal {.smaller}
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What is in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://media.makeameme.org/created/it-worked-fine.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0].message.content)
MultiModal

MultiModal {.smaller}
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Give me a long list of visual search tags/keywords so I can "
"index this image in my visual search index. Respond in JSON format {'labels': ['label1', ...]}",
},
{
"type": "image_url",
"image_url": {
"url": "https://storage.googleapis.com/pai-images/a6d0952a331d40489b216e7f3f1ff6ed.jpeg",
},
},
],
}
],
response_format={"type": "json_object"},
)
print(response.choices[0].message.content)
Code Interpreter (Data Analysis)
- give the LLM access to Python
- your own little data analyst to give tasks to
Fine Tuning
Fine Tuning
Agents
Agents
- todo
Resources
Resources {.smaller}
:::: {.columns}
::: {.column width="33%"}
- Jeremy Howard
- Hamel Husain
- Maxime Labonne
- Sebastian Raschka
- anton
- Teknium
- Simon Willison
- ThursdAI podcast
- Latent Space
:::
::: {.column width="33%"}
- Jay Alammar
- Omar Sanseviero
- Jason Liu
- Omar Khattab
- Wing Liang
- Nous Research
- Alex Albert
- Matt Shumer
- lmsysorg
- Axolotl
- Nathan Lambert :::
::: {.column width="33%"}
- Tanishq Abraham
- Philipp Schmid
- Tim Dettmers
- Eugene Yan
- Georgi Gerganov
- Jim Fan
- swyx
- Charles Frye
- Jonathan Frankle
- Nils Reimers
- Alignment Lab AI
- people I follow :::
::::