Deploying a Remote MCP Server to Modal
Introduction
This video walks through all the content of this post.
In a previous post, I took some notes on MCP as I went through the documentation at a high level.
In this post I will deploy a remote MCP server to Modal, and connect it to Claude Desktop. Claude Desktop, as a host with clients, does not support all the functionality of MCP at the moment. However, it's easy to set up.
If you are not familiar with MCP, I highly suggest reading the MCP documentation.
To follow along you will need to
- have a Modal account and have the Modal CLI installed
- have a Claude Desktop
Tools
Let's build some tools for our MCP Server.
Python Code Execution in a Modal Sandbox
We will build a tool that executes arbitrary python code in a sandboxed environment using Modal Sandboxes. Some relevant docs from Modal on this topic if you are interested:
-
create a python file called
python_sandbox.pywith the following contents:
"""
Note: this could change in the future as modal improves.
But at the time of writing this, the stdout channel does not work well
with from_id at the moment. That is why we make use of the file system.
This module implements a file-based code execution driver in a Modal sandbox.
This module was specifically designed to support detached execution. This means
that you can pass around the Sandbox's object ID and control the same process
from a different process later.
It reads commands from '/modal/io/stdin.txt'; each JSON command must include
a "code" field and a user-supplied "command_id". The execution output (stdout and stderr)
is written to '/modal/io/<command_id>.txt'.
Based off this GIST from Peyton (Modal Developer)
https://gist.github.com/pawalt/7cd4dc56de29e9cddba4d97decaab1ad
"""
import json
import os
import time
from typing import Any, Dict, Optional
from uuid import uuid4
import modal
DRIVER_PROGRAM = """
import json
import os
import sys
import time
from contextlib import redirect_stderr, redirect_stdout
from io import StringIO
from typing import Any, Generator
IO_DATA_DIR = '/modal/io'
os.makedirs(IO_DATA_DIR, exist_ok=True)
STDIN_FILE = os.path.join(IO_DATA_DIR, 'stdin.txt')
with open(STDIN_FILE, 'w') as f:
f.write('')
def tail_f(filename: str) -> Generator[str, None, None]:
# Continuously yields new lines from the file.
with open(filename, 'r') as f:
while True:
line = f.readline()
if not line:
time.sleep(0.1)
continue
yield line
globals: dict[str, Any] = {}
for line in tail_f(STDIN_FILE):
line = line.strip()
print(f'Received line: {line} len: {len(line)}')
if not line:
continue
command = json.loads(line)
if (code := command.get('code')) is None:
print(json.dumps({'error': 'No code to execute'}))
continue
if (command_id := command.get('command_id')) is None:
print(json.dumps({'error': 'No command_id'}))
continue
stdout_io, stderr_io = StringIO(), StringIO()
with redirect_stdout(stdout_io), redirect_stderr(stderr_io):
try:
exec(code, globals)
except Exception as e:
print(f'{type(e).__name__}: {e}', file=sys.stderr)
with open(os.path.join(IO_DATA_DIR, f'{command_id}.txt'), 'w') as f:
f.write(
json.dumps(
{
'stdout': stdout_io.getvalue(),
'stderr': stderr_io.getvalue(),
}
)
)
"""
class ModalSandbox:
IMAGE = modal.Image.debian_slim().pip_install("pandas", "tabulate")
IO_DATA_DIR = "/modal/io"
STDIN_FILE = os.path.join(IO_DATA_DIR, "stdin.txt")
def __init__(
self,
sandbox_id: Optional[str] = None,
timeout: int = 60 * 60,
init_script: Optional[str] = None,
**kwargs: Any,
) -> None:
# check if running Sandbox already exists
if sandbox_id is not None:
existing_sb = self._get_running_sandbox_from_id(sandbox_id)
if existing_sb is not None:
self.sandbox = existing_sb
return
app = modal.App.lookup("python-sandbox", create_if_missing=True)
self.sandbox = modal.Sandbox.create(
"python",
"-c",
DRIVER_PROGRAM,
image=self.IMAGE,
app=app,
timeout=timeout,
**kwargs,
)
if init_script:
self.run_code(init_script)
@classmethod
def _get_running_sandbox_from_id(cls, sb_id: str) -> Optional[modal.Sandbox]:
# Returns None if the sandbox is not running or if the sb_id is not found
# or some error occurs
try:
sb = modal.Sandbox.from_id(sb_id)
except Exception:
return None
# check if the sandbox is running
if sb.poll() is None:
return sb
return None
@property
def sandbox_id(self) -> str:
return self.sandbox.object_id
def terminate(self) -> None:
self.sandbox.terminate()
def run_code(self, code: str) -> Dict[str, str]:
command_id = uuid4().hex
# 1. Write code into a STDIN file on the sandbox.
with self.sandbox.open(self.STDIN_FILE, "a") as f:
f.write(json.dumps({"code": code, "command_id": command_id}))
f.write("\n")
# 2. The sandbox polls this STDIN file for changes,
# executes the added code, then saves the output to a file.
out_file = os.path.join(self.IO_DATA_DIR, f"{command_id}.txt")
# 3. We poll the Sandbox to check if it has created the output file,
# and if so, return the output from the file.
while True:
try:
with self.sandbox.open(out_file, "r") as f:
result = json.load(f)
return result
except FileNotFoundError:
time.sleep(0.1)
This is truly awesome because it allows you to execute arbitrary python code in a sandboxed environment without worrying about the security implications of running code in your local environment. Here is a demo of how to use it locally for testing. This code snippet below within run_code is not running locally, its running in a Modal Sandbox in the cloud.
sb = ModalSandbox()
res = sb.run_code("""
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3]})
print(df)
""")
print(res)
print(res['stdout'])
Image Generation with Qwen Image
Create a python file called image_gen_qwen.py and add the following code below.
Deploy it with modal deploy image_gen_qwen.py.
import os
import modal
# Modal Volume URL configuration
MODAL_WORKSPACE = "drchrislevy" # replace with your modal workspace
MODAL_ENVIRONMENT = "main" # replace with your modal environment
VOLUME_NAME = "qwen_generated_images" # replace with your modal volume name
# Image with required dependencies
image = (
modal.Image.debian_slim()
.apt_install(["git"])
.pip_install(
[
"torch",
"torchvision",
"git+https://github.com/huggingface/diffusers",
"transformers",
"accelerate",
"pillow",
"sentencepiece",
"python-dotenv",
]
)
)
app = modal.App("qwen-image-generator", image=image)
hf_hub_cache = modal.Volume.from_name("hf_hub_cache", create_if_missing=True)
images_volume = modal.Volume.from_name(VOLUME_NAME, create_if_missing=True)
@app.cls(
image=image,
gpu="H100",
secrets=[
modal.Secret.from_name("huggingface-secret"),
],
timeout=60 * 10,
volumes={
"/root/.cache/huggingface/hub/": hf_hub_cache,
"/root/generated_images": images_volume,
},
scaledown_window=60 * 60,
max_containers=2,
)
@modal.concurrent(max_inputs=1)
class QwenImageGenerator:
@modal.enter()
def setup(self):
"""Load Qwen-Image model once per container"""
import torch
from diffusers import DiffusionPipeline
print("Loading Qwen/Qwen-Image model...")
# Set device and dtype (CUDA is available)
self.torch_dtype = torch.bfloat16
self.device = "cuda"
# Load the pipeline
self.pipe = DiffusionPipeline.from_pretrained(
"Qwen/Qwen-Image",
torch_dtype=self.torch_dtype,
cache_dir="/root/.cache/huggingface/hub",
)
self.pipe = self.pipe.to(self.device)
print("Model loaded successfully!")
# Set up volume path for storing images
self.images_path = "/root/generated_images"
# Define aspect ratios
self.aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472),
}
def generate_image(
self,
prompt: str,
negative_prompt: str = "",
aspect_ratio: str = "16:9",
true_cfg_scale: float = 3.5,
seed: int = 42,
randomize_seed=False,
num_inference_steps: int = 50,
):
"""Generate image from text prompt and save to Modal Volume"""
import random
import uuid
from datetime import datetime
import numpy as np
import torch
MAX_SEED = np.iinfo(np.int32).max
if randomize_seed:
seed = random.randint(0, MAX_SEED)
generator = torch.Generator(device=self.device).manual_seed(seed)
print(f"Generating image for prompt: {prompt}")
# Get dimensions from aspect ratio
if aspect_ratio in self.aspect_ratios:
width, height = self.aspect_ratios[aspect_ratio]
else:
width, height = self.aspect_ratios["16:9"] # default
# Generate image
image = self.pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=width,
height=height,
num_inference_steps=num_inference_steps,
true_cfg_scale=true_cfg_scale,
generator=generator,
).images[0]
# Create unique filename
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
unique_id = str(uuid.uuid4())[:8]
filename = f"qwen_generated_{timestamp}_{unique_id}.png"
file_path = os.path.join(self.images_path, filename)
# Save image to Modal Volume
try:
image.save(file_path, format="PNG")
print(f"Image saved successfully to volume: {file_path}")
# Generate Modal Volume URL
# Format: https://modal.com/api/volumes/{workspace}/{env}/{volume_name}/files/content?path={filename}
image_url = f"https://modal.com/api/volumes/{MODAL_WORKSPACE}/{MODAL_ENVIRONMENT}/{VOLUME_NAME}/files/content?path={filename}"
return {
"image_url": image_url,
"filename": filename,
"file_path": file_path,
"prompt": prompt,
"negative_prompt": negative_prompt,
"aspect_ratio": aspect_ratio,
"dimensions": {"width": width, "height": height},
"volume_path": f"/root/generated_images/{filename}",
}
except Exception as e:
print(f"Error saving to volume: {e}")
raise
@modal.fastapi_endpoint(
method="POST",
docs=True,
)
def generate_image_endpoint(
self,
prompt: str,
negative_prompt: str = "",
aspect_ratio: str = "16:9",
true_cfg_scale: float = 4.0,
seed: int = 42,
randomize_seed: bool = False,
num_inference_steps: int = 50,
):
"""Public FastAPI endpoint for image generation"""
return self.generate_image(
prompt=prompt,
negative_prompt=negative_prompt,
aspect_ratio=aspect_ratio,
true_cfg_scale=true_cfg_scale,
seed=seed,
randomize_seed=randomize_seed,
num_inference_steps=num_inference_steps,
)
Once you deploy the endpoint you will get a URL: For this demo the url is
https://drchrislevy--qwen-image-generator-qwenimagegenerator-gen-5fbcf5.modal.run/
You can always test it with the docs at https://drchrislevy--qwen-image-generator-qwenimagegenerator-gen-5fbcf5.modal.run/docs/
We can test it quickly with the requests library.
import requests
endpoint_url = "https://drchrislevy--qwen-image-generator-qwenimagegenerator-gen-5fbcf5.modal.run/"
response = requests.post(
endpoint_url,
params={
"prompt": 'A beautiful view looking down a road with cute houses on either side and mountains in the background.',
"negative_prompt": "blurry, low quality, distorted",
"aspect_ratio": "16:9",
"true_cfg_scale": 4.0,
"randomize_seed": True,
"num_inference_steps": 50,
},
timeout=120,
)
response.json()

Deploying the MCP Server with FastMCP and Modal
Now create a final file called mcp_demo.py with the following contents.
We add some other fake tools/resources/sampling to show that
the FastMCP library supports those features, even though the Claude Desktop do not fully yet.
# server.py
import modal
image = (
modal.Image.debian_slim()
.pip_install("fastapi[standard]", "fastmcp>=2.3.2")
.add_local_file("posts/mcp/python_sandbox.py", remote_path="/root/python_sandbox.py")
)
app = modal.App("fastmcp-modal-demo", image=image)
@app.function(scaledown_window=60 * 60)
@modal.concurrent(max_inputs=100)
@modal.asgi_app()
def mcp_asgi():
# Everything below runs inside the Modal container
from fastmcp import Context, FastMCP
from python_sandbox import ModalSandbox
from starlette.responses import JSONResponse
sb = ModalSandbox()
mcp = FastMCP(
name="HelpfulAssistant",
instructions="""This server provides some useful tools for the user.""",
)
@mcp.tool
def execute_python_code(code: str) -> dict:
"""Run arbitrary python code in a sandboxed environment. It is stateful and persistent between calls.
Install packages with: os.system("pip install <package_name>")
"""
return sb.run_code(code)
@mcp.tool
def text2image(
prompt: str,
negative_prompt: str = "blurry, low quality, distorted",
aspect_ratio: str = "16:9",
true_cfg_scale: float = 4.0,
randomize_seed: bool = True,
num_inference_steps: int = 50,
seed: int = 42,
) -> dict:
"""Given the text prompt and other parameters,
uses an AI text2image model to generate an image and return the image url.
Always return at least the image url so the user can see the image."""
import requests
endpoint_url = "https://drchrislevy--qwen-image-generator-qwenimagegenerator-gen-5fbcf5.modal.run/"
response = requests.post(
endpoint_url,
params={
"prompt": prompt,
"negative_prompt": negative_prompt,
"aspect_ratio": aspect_ratio,
"true_cfg_scale": true_cfg_scale,
"randomize_seed": randomize_seed,
"num_inference_steps": num_inference_steps,
"seed": seed,
},
timeout=120,
)
return response.json()
@mcp.resource("users://{user_id}/profile")
def get_user_profile(user_id: int) -> dict:
"""Retrieves a user's profile by ID."""
# The {user_id} in the URI is extracted and passed to this function
return {"id": user_id, "name": f"User {user_id}", "status": "active"}
@mcp.resource("data://config")
def get_config() -> dict:
"""Provides application configuration as JSON."""
return {
"theme": "dark",
"version": "1.2.0",
"features": ["tools", "resources"],
}
# Optional plain HTTP health check (easy to curl)
@mcp.custom_route("/health", methods=["GET"])
async def health(_req):
return JSONResponse({"status": "ok"})
@mcp.prompt
def ask_about_topic(topic: str) -> str:
"""Generates a user message asking for an explanation of a topic."""
return f"Can you please explain the concept of '{topic}'?"
@mcp.tool
async def analyze_sentiment(text: str, ctx: Context) -> dict:
"""Analyze the sentiment of text using the client's LLM."""
prompt = f"""Analyze the sentiment of the following text as positive, negative, or neutral.
Just output a single word - 'positive', 'negative', or 'neutral'.
Text to analyze: {text}"""
# Request LLM analysis
response = await ctx.sample(prompt)
# Process the LLM's response
sentiment = response.text.strip().lower()
# Map to standard sentiment values
if "positive" in sentiment:
sentiment = "positive"
elif "negative" in sentiment:
sentiment = "negative"
else:
sentiment = "neutral"
return {"text": text, "sentiment": sentiment}
# Expose the MCP server as an ASGI app.
# Default transport is Streamable HTTP; we mount at /mcp
return mcp.http_app(path="/mcp")
Deploy the MCP server with modal deploy mcp_demo.py.
The modal endpoint url will look something like https://drchrislevy--fastmcp-modal-demo-mcp-asgi.modal.run
but the MCP server is available at https://drchrislevy--fastmcp-modal-demo-mcp-asgi.modal.run/mcp. This latter
link is the path for the remote MCP server.
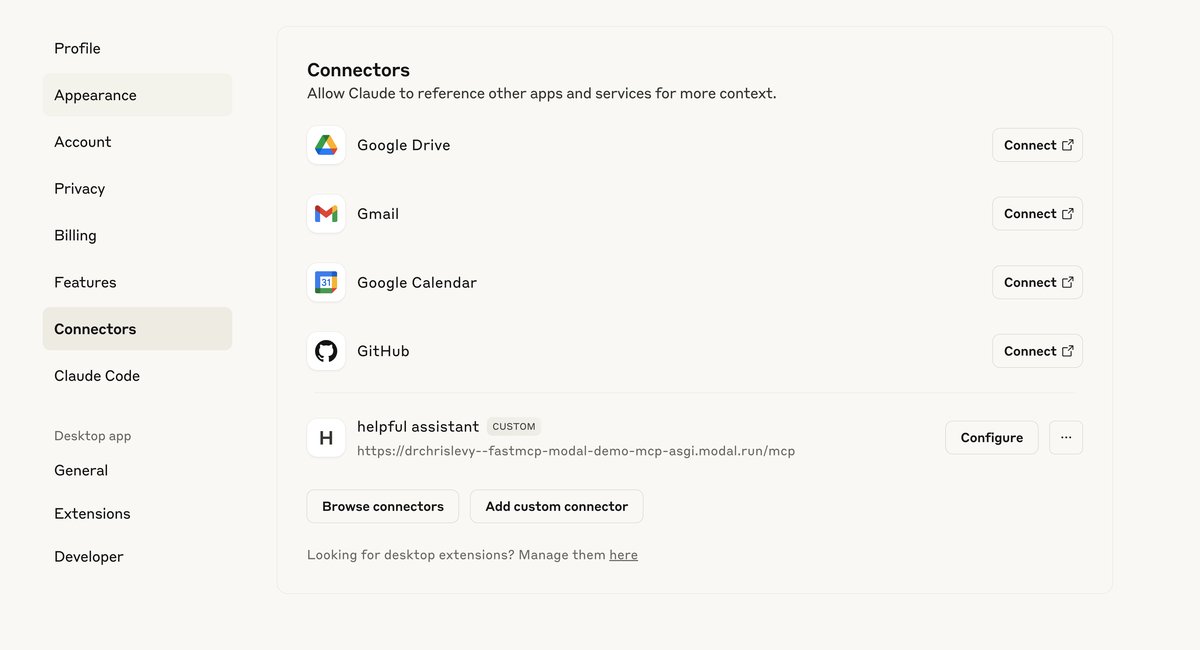
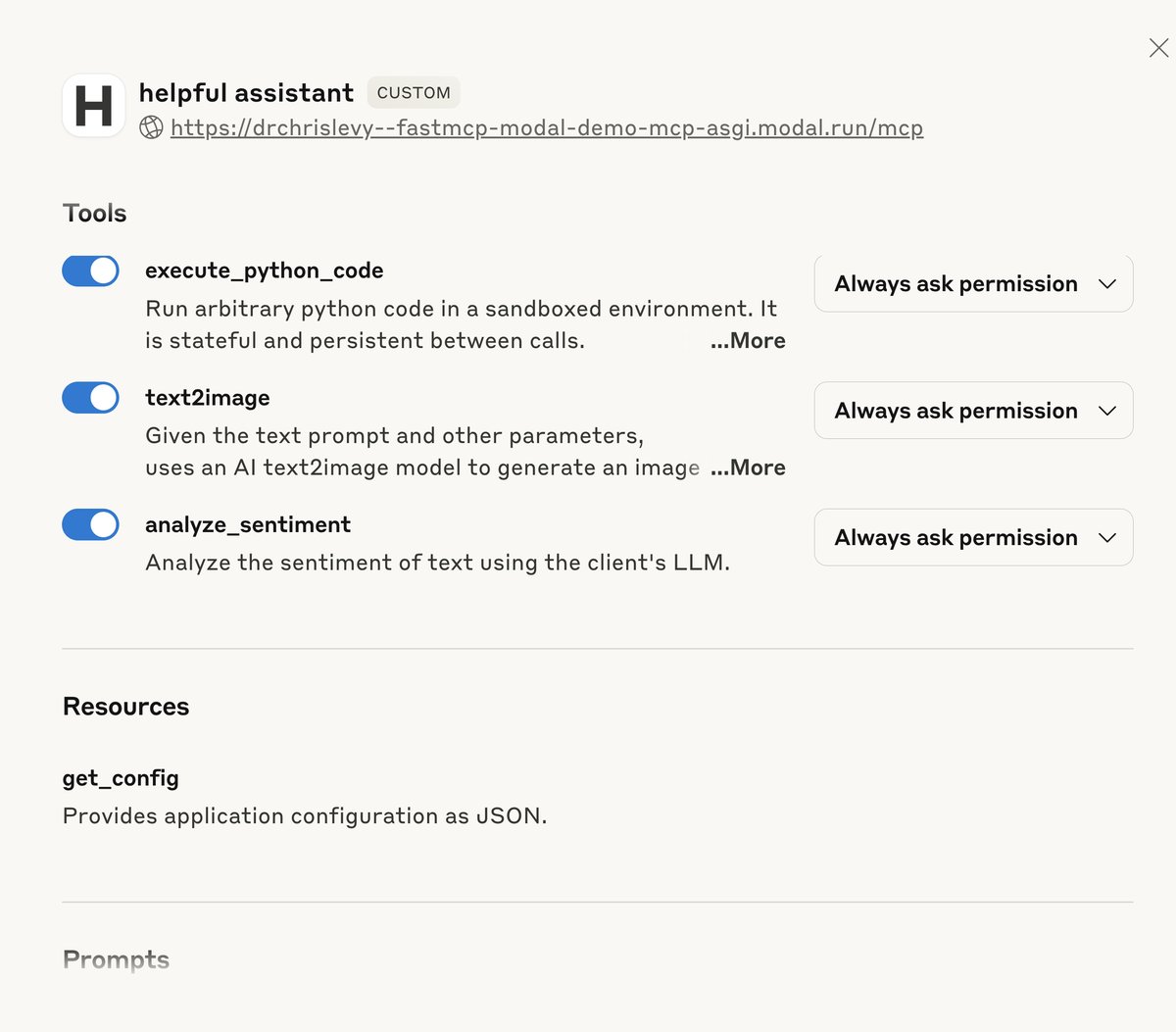
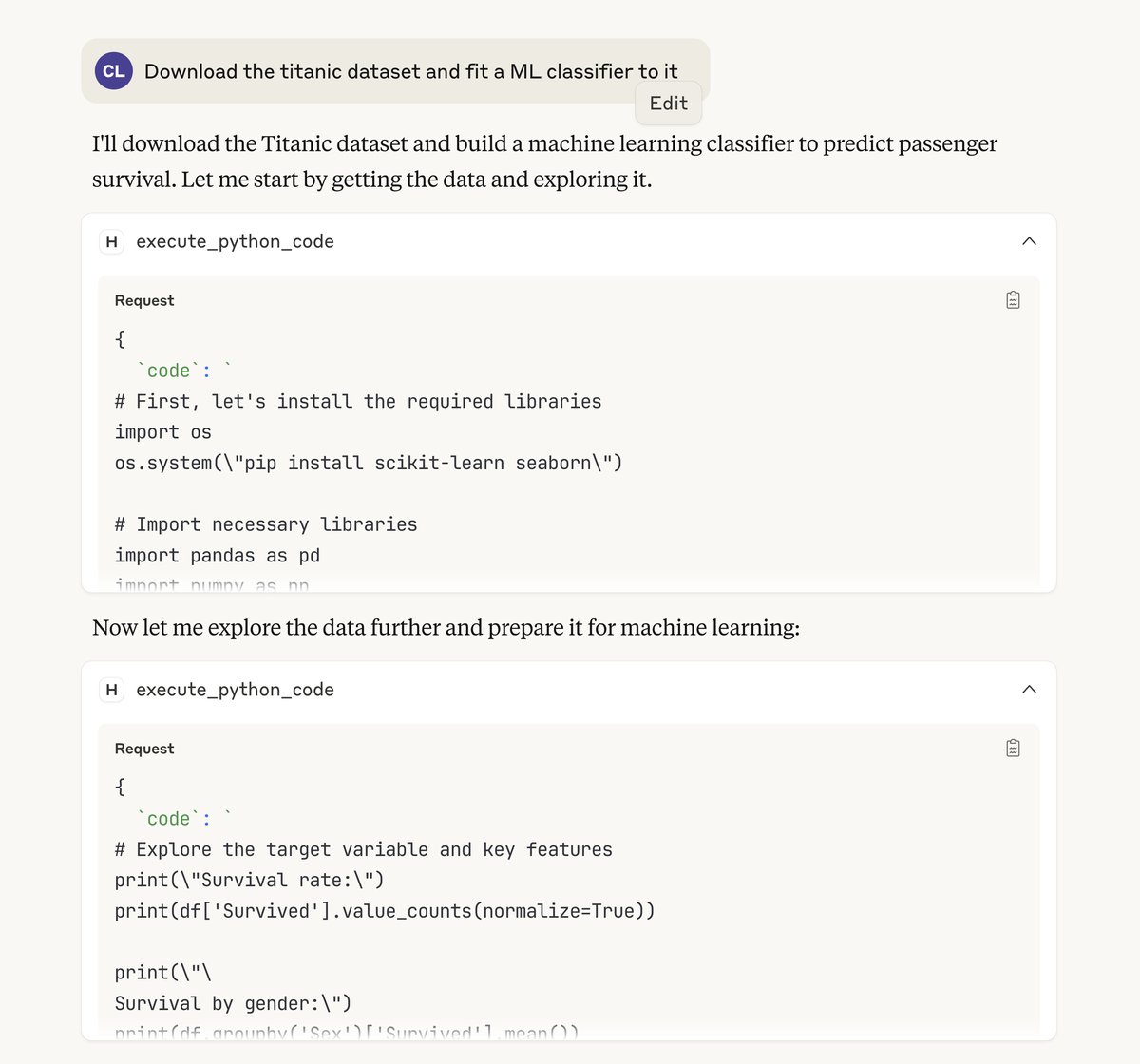
You can then add the endpoint url to your Claude Desktop and try out the MCP server there.
Similarly, you could also configure it in your Cursor IDE, etc. In Cursor your mcp.json
could look something like
{
"mcpServers": {
"helpful-assistant": {
"transport": "streamable-http",
"url": "https://drchrislevy--fastmcp-modal-demo-mcp-asgi.modal.run/mcp/"
}
}
}