Fine-Tuning ModernBERT For Classification Tasks on Modal
Intro
First go and read the ModernBert blog post announcement here.
If you are interested I wrote a little about transformers (encoders and decoders) in my previous blog posts here and here. I also have written previously about using Modal here and here and here.
Encoder Models Generate Embedding Representations
This section gives a very quick rundown on how encoder models encode text into embeddings.
from transformers import AutoModel, AutoTokenizer
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id)
model
text = "The capital of Nova Scotia is Halifax."
inputs = tokenizer(text, return_tensors="pt")
inputs
# Get embeddings
outputs = model(**inputs, output_hidden_states=True)
outputs.keys()
# Tuple containing outputs from every layer in the model
print(len(outputs.hidden_states))
set([x.shape for x in outputs.hidden_states])
# last_hidden_state
# Single tensor representing the final layer's output
# [batch_size, sequence_length, hidden_size]
outputs.last_hidden_state.shape
outputs.last_hidden_state
The reason we get an embedding for each token (11 in this example) is because BERT ( ModernBERT) are contextual embedding models, meaning they create representations that capture each token's meaning based on its context in the sentence. Each token gets its own 768-dimensional embedding vector.
for position in range(len(inputs.input_ids[0])):
token_id = inputs.input_ids[0][position]
decoded_token = tokenizer.decode([token_id])
embedding = outputs.last_hidden_state[0][position]
print(f"Position {position}:")
print(f"Input Token ID: {token_id}")
print(f"Input Token: '{decoded_token}'")
print(f"Embedding Shape: {embedding.shape}")
print("-" * 50)
For downstream tasks with BERT-like models (including ModernBERT), there are typically two main approaches for generating
a single embedding for the entire input text:
[CLS] Token Embedding (Most Common)
# Get the [CLS] token embedding (first token, index 0)
cls_embedding = outputs.last_hidden_state[0][0] # Shape: [768]
cls_embedding.shape
Mean Pooling (Alternative Approach)
# Mean pooling - take average of all tokens
mean_embedding = outputs.last_hidden_state[0].mean(dim=0) # Shape: [768]
mean_embedding.shape
The [CLS] token is specifically designed to capture sentence-level information and is most commonly used for classification tasks. This is because BERT models are trained to use this token to aggregate information from the entire sequence.
Fine-Tuning ModernBERT for Classification
When I first learned about fine-tuning transformer encoder models for classification tasks, my favorite resource was the book Natural Language Processing with Transformers: Building Language Applications with Hugging Face. It's still relevant and a great resource. In particular, checkout Chapter 2 which walks through classification tasks. In that chapter the authors first train a simple classifier on top of the [CLS] token embeddings. In that case the model is frozen and only used as a feature extractor. The other approach is to fine-tune the entire model together with a classification head. It's this latter approach that I'll show you how to do here.
Place your wandb api key in a .env file like this: WANDB_API_KEY=<>
create the filetrainer.py and place it at the root of your project folder alongside the .env file. The full code is below but you can also find it here.
Training Code
Here is all the code for the trainer.py file.
At the beginning of the file you can adjust the dataset, model, learning rate, batch size, epochs, class labels, column names, etc.
It's expected to use a Hugging Face dataset and it's expected that you will have to change these variables based on the dataset you are using.
You can also make edits anywhere else in the code as well but when you are first starting out it's best to keep the code simple and only make changes to the variables at the beginning of the file.
When you run modal run trainer.py it will execute the code within the function main().
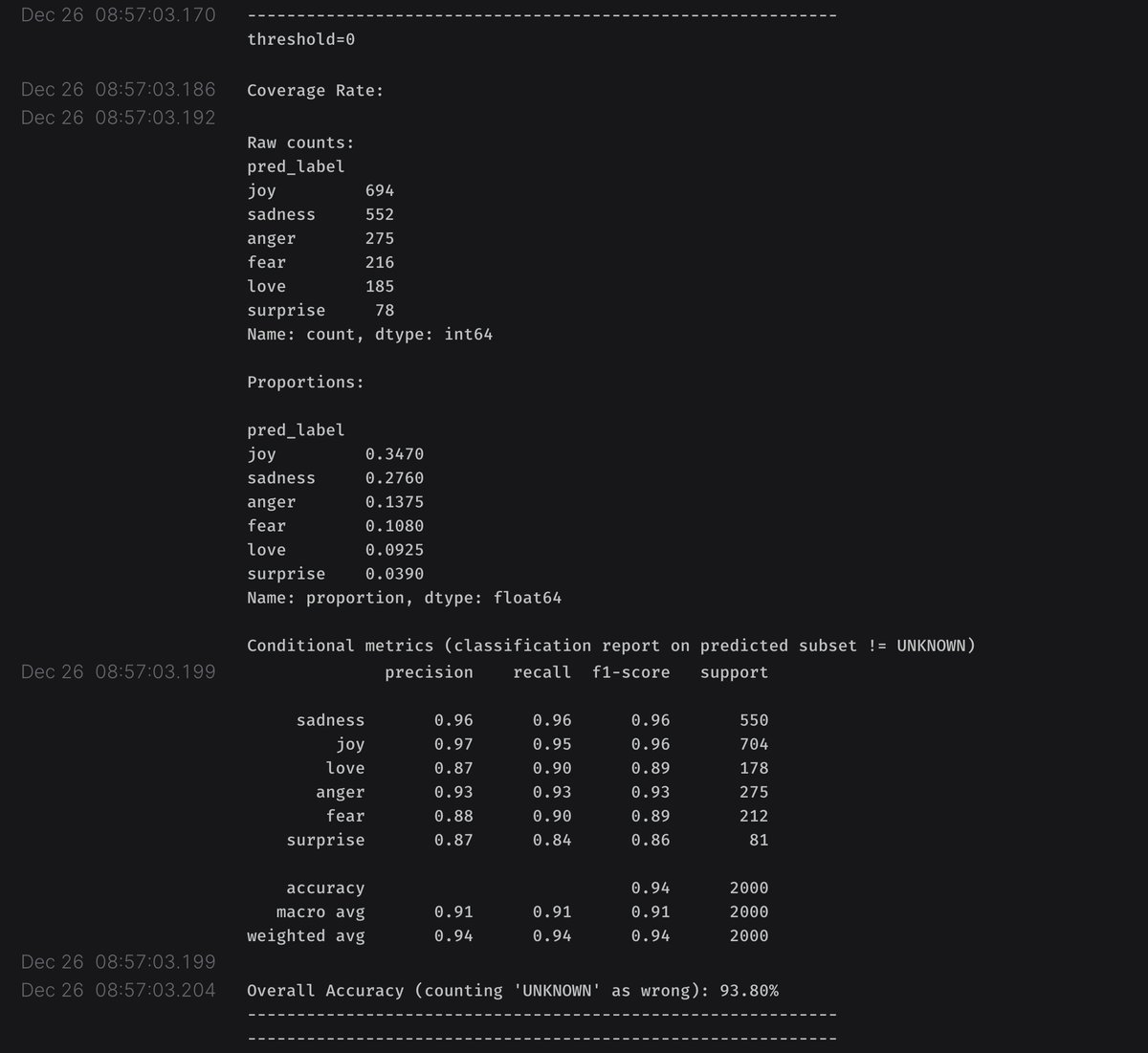
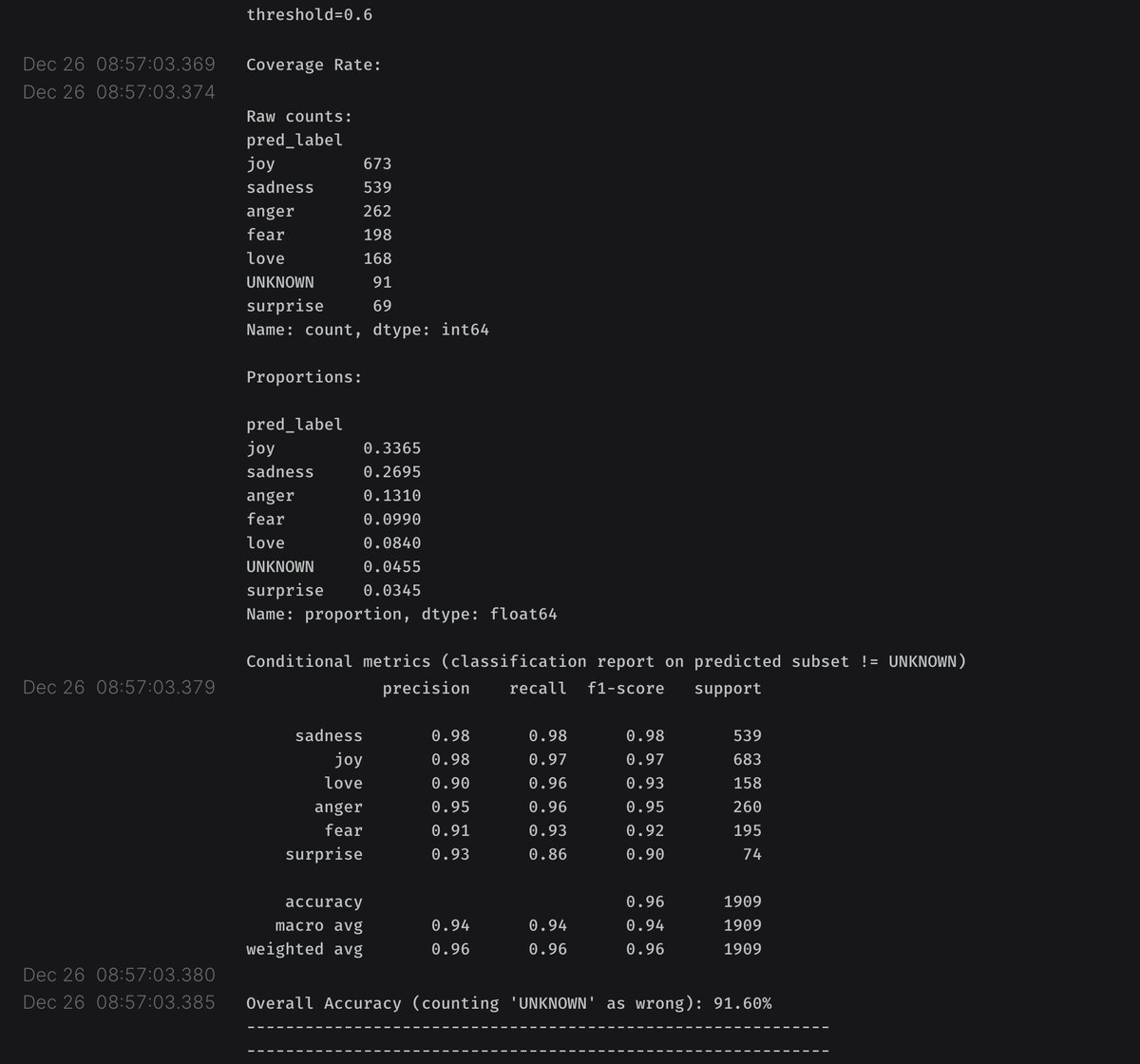
By default it trains a model and then evaluates it on the validation split
You can do whatever else you want here in the main() function. For example, you could comment out the training logic and just run an evaluation on some checkpoint.
There are two main modal functions which each run in their own container. See the functions decorated with @modal.method(), which are train_model and eval_model.
If you want to run different training runs or evaluation runs just edit the file and kick off the jobs by executing modal run trainer.py from the command line. Remember modal will take care of spinning up the containers and running the code!
You can use the command modal run --detach trainer.pywhich lets the app continue running even if your client disconnects.
In either case you will see live logs directly in your local terminal, even though the containers are running in the cloud.
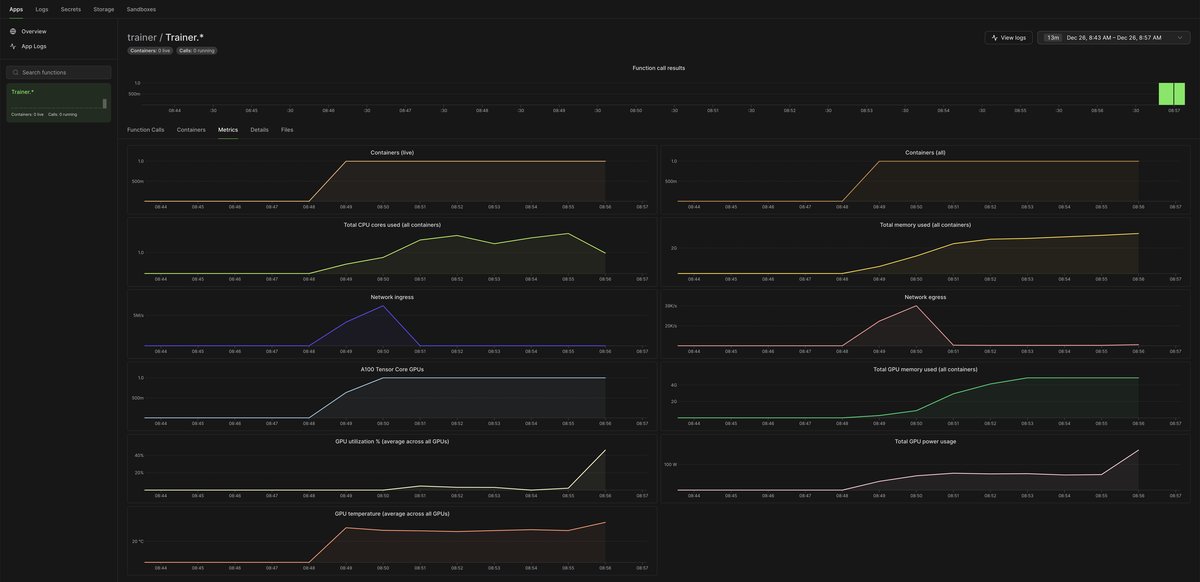
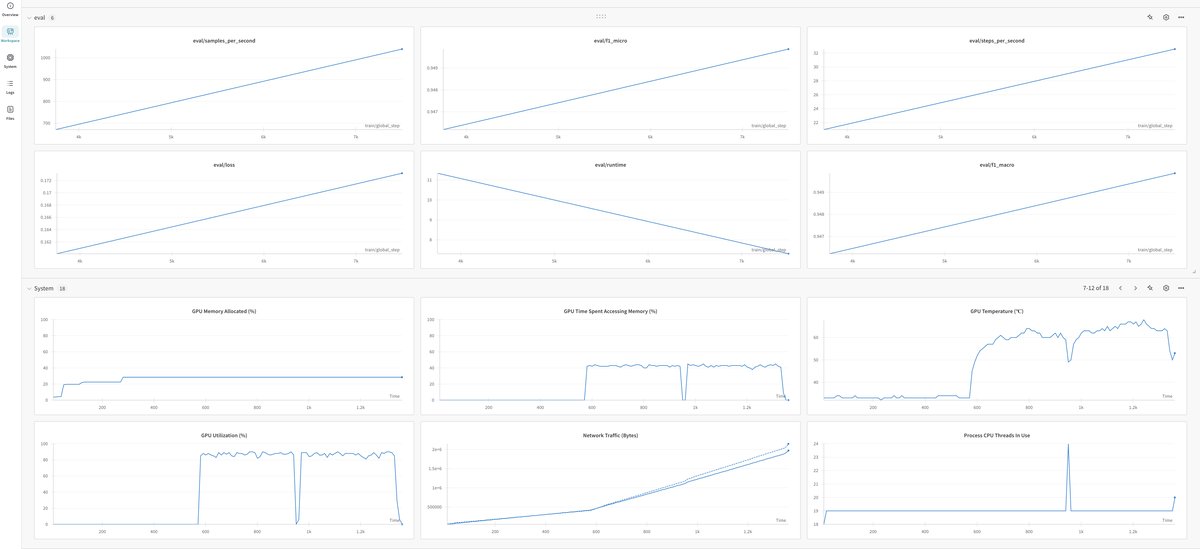
You can also follow along with logs and container metrics in the Modal UI dashboard.
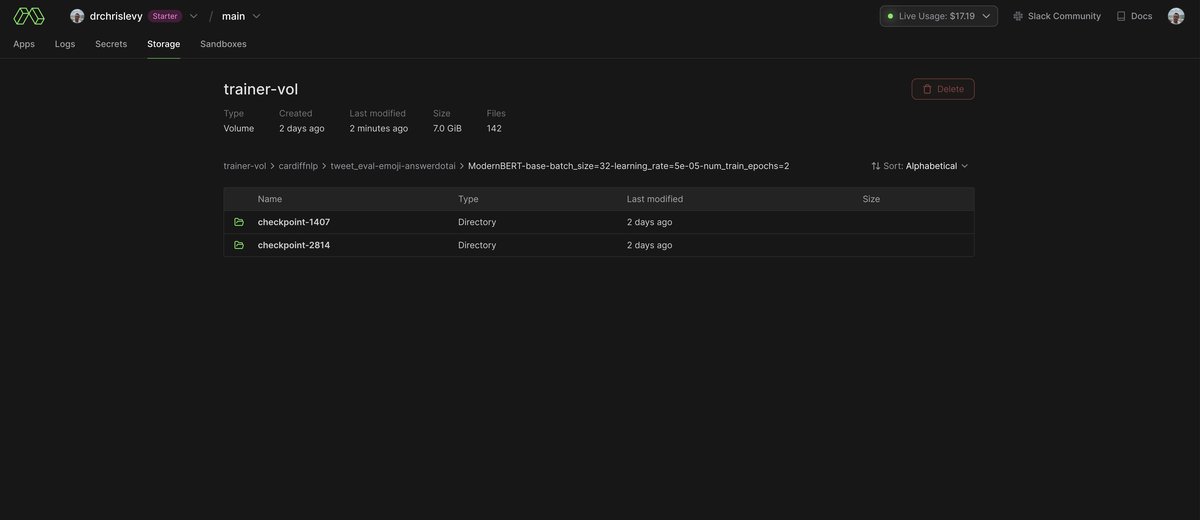
All the datasets and models are stored in the Modal volumes. You can see them in the Modal UI dashboard.
Here are is the trainer.py file. You can also find it here on github.
Run The Trainer
All of these training runs can be executed from the command line by running modal run trainer.py
after making minor edits to the trainer.py file. You can even run them all in parallel,
because Modal will take care of spinning up the containers and running the code!
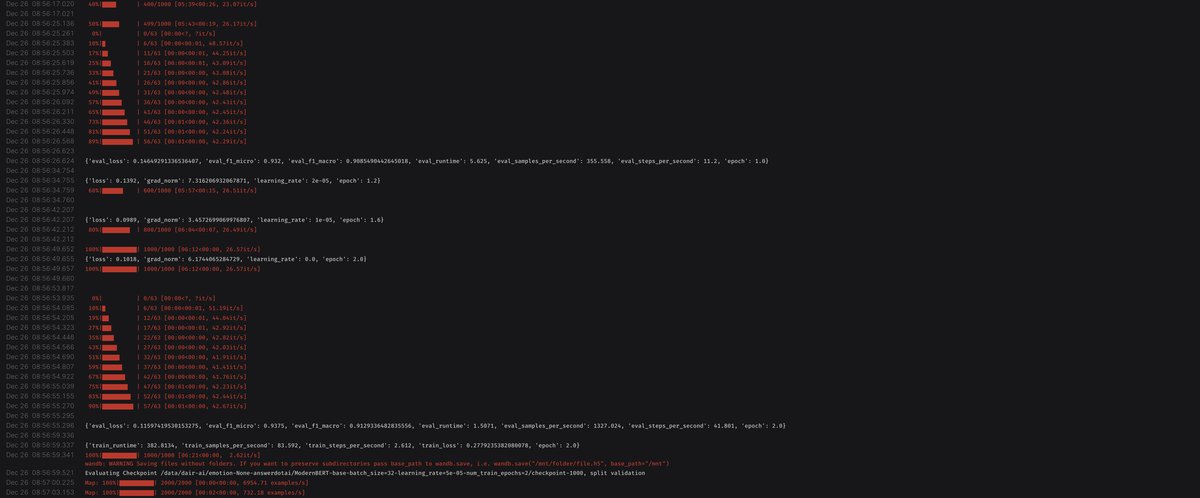
Here are some random screen shots from the Modal UI dashboard showing containers, GPU metrics, volumes for storing datasets and checkpoints, and log outputs.
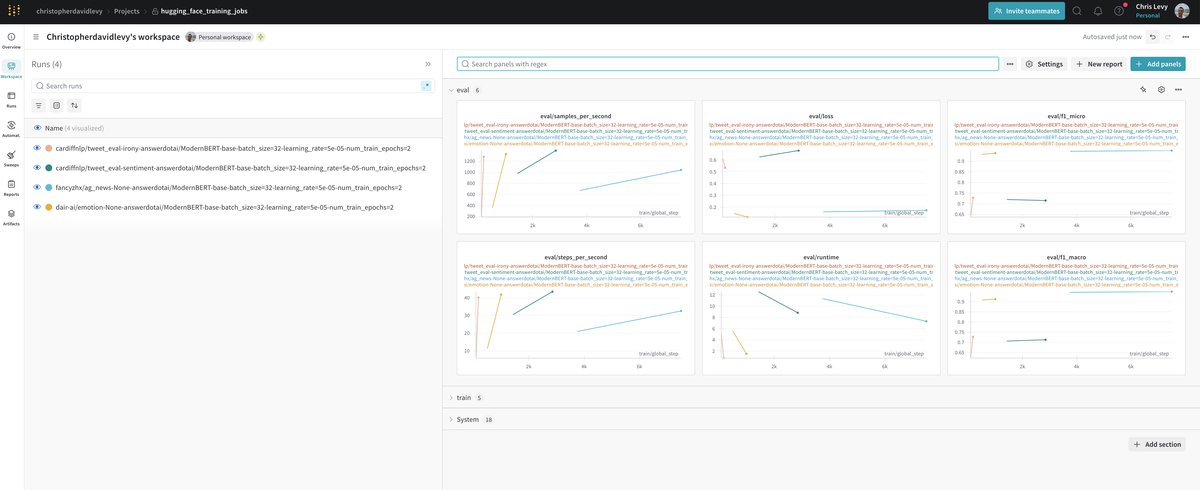
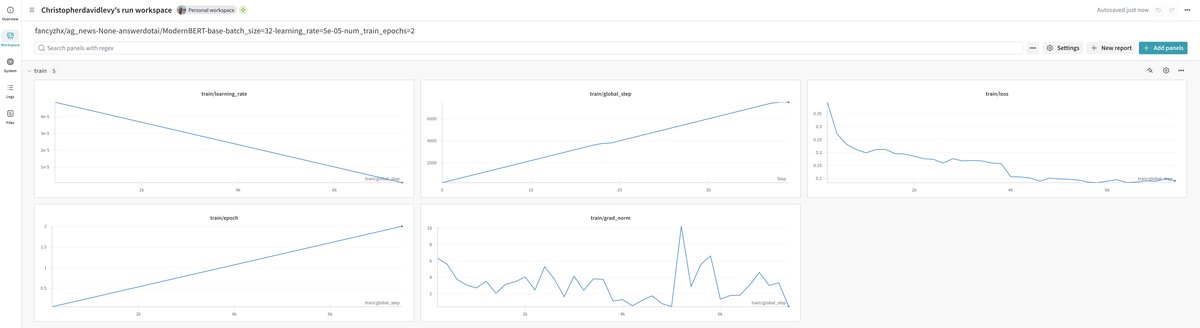
Here are some screen shots from the wandb dashboard. There are public wandb runs for each of the training runs below.
Emotion Dataset
By default the trainer will use the "dair-ai/emotion" dataset which predicts the emotion of a text.
You can easily switch to a different dataset, in this case I used the "fancyzhx/ag_news" dataset.
All I switched in the trainer.py file were these lines:
To test out the longer context window of ModernBERT, I created a synthetic dataset with longer texts.
These texts consists of synthetic social media posts. For each row in the dataset there is a list of input tweets concatenated together and a corresponding label. I made this dataset using various LLMS such as gpt-4o-mini, claude-3-5-sonnet-20241022, gemini-2.0-flash-exp, and deepseek-chat-v3. The prompts for creating the dataset are in the prompts.py file which can be found here. The system prompt was also crafted mostly by an LLM and I made some minor edits to it. The dataset is just a toy dataset and should not be used for anything serious. It probably has issues since I hacked it together rather quickly.
I uploaded the dataset to the Hugging Face Hub and you can find it here.
To run the trainer on this dataset make these edits to the trainer.py file:
I hope this code can start as a launching point for your own fine-tuning experiments with encoder models and ModernBERT.
If you were not familiar with Modal, I hope this shows you how easy it is to get started.
I think minor changes may be needed to get this training with flash attention 2. You will see some commented out parts of my code
with regards to choosing attn_implementation="flash_attention_2". I'm not sure if that is needed or not. I think I am
installing the flash attention 2 package but I'm not sure if it's being used during training. If anyone knows, hit up on X.
I did try running different variations but couldn't really see how to tell if it was all running properly or not.